
雷锋网按: 谷歌去年年中推出的 TPUv1 一度让英伟达感遭到要挟将近,而如今的谷歌 TPU 二代 TPUv2 则着着实实得将这份要挟变成了理想,去年的评测中英伟达 Tesla V100 尚能不惧谷歌 TPUv1 的应战,但是如今谷歌 TPU 二代来了,英伟达 Tesla V100 尚能战否?

以下为 RiseML 对谷歌 TPUv2 和英伟达 Tesla V100 的比照评测,雷锋网 (大众号:雷锋网) (大众号:雷锋网) AI 科技评论将其内容编译如下。
谷歌在 2017 年为减速深度学习开发了一款的定制芯片,张量处置单元 v2 (TPUv2)。TPUv2 是谷歌在 2016 年初次地下的深度学习减速云端芯片 TPUv1 的二代产品,被以为有着替代英伟达 GPU 的潜在实力。RiseML 此前撰写过一篇谷歌 TPUv2 的初体验,并随后收到了大家「将谷歌 TPUv2 与英伟达 V100 GPU 停止比照评测」的少量迫切要求。
但是将这两款深度学习减速芯片停止公道而又有意义的比照评测并非易事。同时由于这两款产品的对业界将来开展的重要水平和以后深度详细评测的缺失,这让我们深感需求自行对这两款重磅云端芯片停止深度评测。我们在评测进程中也尽能够地站在芯片统一单方倾听不赞同见,因而我们也同时与谷歌和英伟达的工程师树立联络并让他们在本次评测文草稿阶段留下各自的意见。以上措施使得我们做出了针对 TPUv2 和 V100 这两款云端芯片的最片面深度比照评测。
实验设置
我们用四个 TPUv2 芯片(来自一个 Cloud TPU 设备)比照四个英伟达 V100 GPU,两者都具有 64GB 内存,因此可以训练相反的模型和运用异样的批量大小。该实验中,我们还采用了相反的训练形式:四个 TPUv2 芯片组成的一个 Cloud TPU 来运转一种同步数据并行散布式训练,英伟达一侧也是异样应用四个 V100 CPU。
模型方面,我们决议运用图像分类的实践规范和参考点在 ImageNet 上训练 ResNet-50 模型。虽然 ResNet-50 是可地下运用的参考实例模型,但是如今还没有可以单一的模型完成支持在 Cloud TPU 和多个 GPU 上停止模型训练。
关于 V100,英伟达建议运用 MXNet 或许 TensorFlow 的完成,可以在 Nvidia GPU Cloud 平台上的 Docker images 中运用它们。但是,我们发现 MXNet 或许 TensorFlow 完成直接拿来运用的话,在多 GPU 和对应的大训练批量下并不能很好地收敛。这就需求加以调整,尤其是在学习率的设置方面。
作为替代,我们运用了来自 TensorFlow 的 基准库(benchmark repository),并在 tensorflow/tensorflow:1.7.0-gpu, CUDA 9.0, CuDNN 7.1.2 下在 Docker image 中运转它。它分明快过英伟达官方引荐的 TensorFlow 完成,而且只比 MXNet 完成慢 3%。不过它在批量下收敛得很好。这就有助于我们在异样平台(TensorFlow 1.7.0)下运用相反框架,来对两个完成停止比拟。
云端 TPU 这边,谷歌官方引荐运用来自 TensorFlow 1.7.0 TPU repository 的 bfloat16 完成。TPU 和 GPU 完成应用各个架构的混合精度训练计算以及运用半精度存储最大张量。
针对 V100 的实验,我们在 AWS 上运用了四个 V100 GPU(每个 16 GB 内存)的 p3.8xlarge 实例(Xeon E5-2686@2.30GHz 16 核,244 GB 内存,Ubuntu 16.04)。针对 TPU 实验,我们运用了一个小型 n1-standard-4 实例作为主机(Xeon@2.3GHz 双核,15GB 内存,Debian 9),并为其配置了由四个 TPUv2 芯片(每个 16 GB 的内存)组成的云端 TPU(v2-8)。
我们停止了两种不同的比照实验,首先,我们在人工分解自然场景(未加强数据)下,察看了两者在每秒图像处置上的原始表现,详细来说是数据吞吐速度(每秒处置的图像数目)。这项比照与能否收敛有关,而且确保 I / O 中无瓶颈或无加强数据影响后果。第二次比照实验,我们察看了两者在 ImageNet 上的精确性和收敛性。
数据吞吐速度后果
我们在人工分解自然场景(未加强数据)下,以每秒图像处置的方式观测了数据吞吐速度,也就是,在不同批量大小下,训练数据也是在运转进程中发明的。同时需求留意,TPU 的官方引荐批量大小是 1024,但是基于大家的实验要求,我们还在其他批量大小下停止了两者的功能测试。
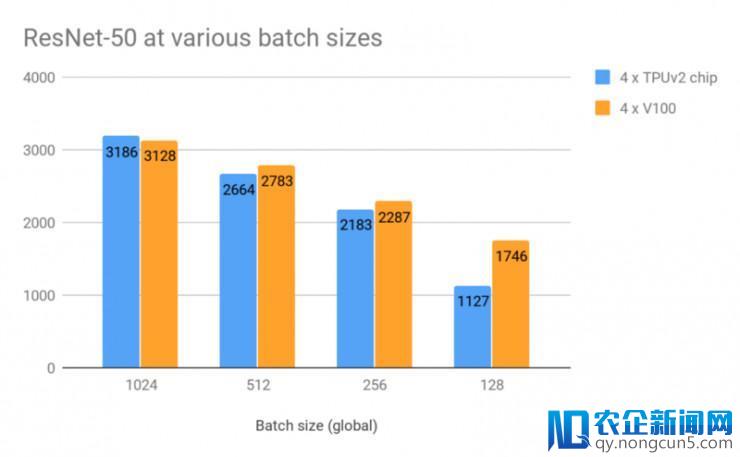
在生成的数据和没无数据加强的设置下,在各种批量大小下测试两者的每秒图像处置功能表现。批量大小为「global」总计的,即 1024 意味着在每个步骤中每个 GPU / TPU 芯片上的批量大小为 256
当批量大小为 1024,两者在数据吞吐速度中并无实践区别!谷歌 TPU 有约 2% 的细微抢先优势。大小越小,两者的功能表现会越降低,这时 GPU 就表现地稍好一点。但如上所述,目前这些批量大小关于 TPU 来说并不是一个引荐设置。
依据英伟达的官方建议,我们还在 MXNet 上运用 GPU 做了一个实验,运用的是 Nvidia GPU C本次涌现的 AI、区块链和物联网热潮不同于以往,将对产业、社会和生活产生真正堪称“颠覆性”的变革。IT 技术人员需要全方位地“换脑”:对原有的知识结构进行全面刷新,全面升级。loud 上提供的 Docker image (mxnet:18.03-py3) 内的 ResNet-50 完成。在批量大小为 768 时(1024 太大),GPU 能每秒处置 3280 张图像。这比下面 TPU 最好的功能表现还要快 3%。但是,就像下面那样,在批量大小同为 168 时,多 GPU 上 MXNet 收敛得并不好,这也是我们为什么关注两者在 TensorFlow 完成上的表现状况,包括上面提及的也是一样。
云端本钱
如今 Google Cloud 曾经开放了云端 TPU(四个 TPUv2 芯片)。只要在被要求计算时,云端 TPU 才会衔接到 VM 实例。云端测试方面,我们思索运用 AWS 来测试英伟达 V100(由于 Google Cloud 以后仍不支持 V100)。基于下面的测试后果,我们总结出了两者在各自平台和 provider 上的每秒处置图像数量上的破费本钱(美元)。
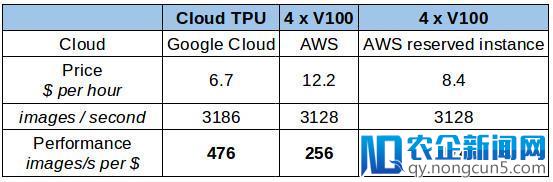
每秒图像处置上的本钱(美元)
在上表所示的本钱下,云端 TPU 显然是个赢者。但是,当你思索临时租用或许购置硬件(云 TPU 如今还没有方法买到),状况能够会不同。以下情况还包括当租用 12 个月时的状况(在 AWS 上的 p3.8xlarge 保存实例的价钱(无预付款))。这种租用状况将分明得将价钱降低至每 1 美元处置 375 张图像的本钱。
GPU 这边有一个更有意思的购置选项可以思索,例如 Cirrascale 就提供了四个 V100 GPU 效劳器的月租效劳,月租金 7500 美元(约 10.3 美元/小时)。但是由于硬件会因 AWS 上的硬件配置(CPU 品种,内存以及 NVlink 支持等等)的不同而改动,而以 benchmarks 为基准的比照评测要求的是直接的比照(非云端租用)。
正确率和收敛
除报告两者的原始功能之外,我们还想验证计算(computation)是「有意义」的,也就是指,完成收敛至好的后果。由于我们比拟的是两种不同的完成,所以一些误差是在意料之中的。因而,这是一项不只仅是关于硬件速度,还会触及到完成质量的比照评测。TPU 的 ResNet-50 完成中参加了十分高计算强度的图像预处置进程,这实践上牺牲了一局部数据吞吐速度。谷歌给出的完成中就是这样设计的,稍后我们也会看到这种做法的确取得了报答。
我们在 ImageNet 数据集上训练模型,训练义务是将一张图像分类至如蜂鸟,墨西哥卷饼或披萨的 1000 个类别。这个数据集由训练用的 130 万张图像(约 142 GB)以及 5 万张用于验证的图像(约 7 GB)组成。
我们在批量大小为 1024 的状况下,对模型停止了 90 个时期的训练,并将数据验证的后果停止了比拟。我们发现,TPU 完成一直坚持每秒处置 2796 张图像的进程,同时 GPU 完成坚持每秒处置 2839 张。这也是依据下面数据吞吐速度后果所得的区别,我们是在未停止数据加强和运用生成的数据的状况下,对 TPU 和 GPU 停止的原始速度比拟。
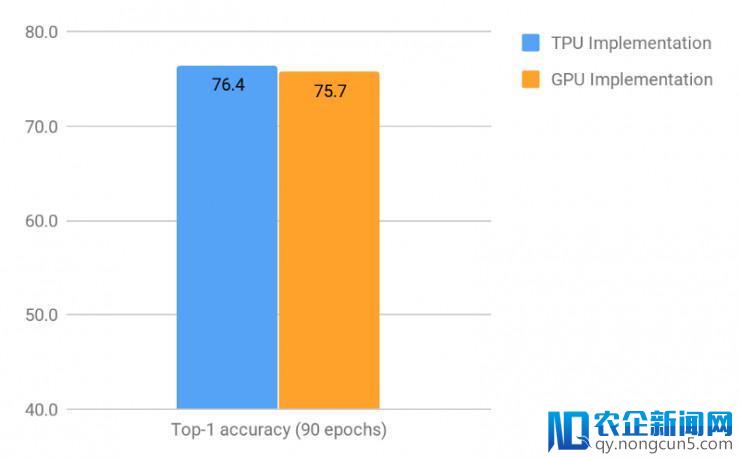
两个完成在停止了 90 个时期训练后的首位精确率(即只思索每张图像具有最高可信度的预测状况下)
如上图所示,TPU 完成 停止了 90 个时期训练后的首位精确率比 GPU 多 0.7%。这在数值上能够看起来是很小的差异,但是在两者曾经十分高的程度上停止提升是极度困难的,以及在两者在实践使用场景中,即使是如此小差距的提升也将最终招致在表现发生大相径庭。
让我们来看一下在不同的训练时期模型学习辨认图像的首位精确率。
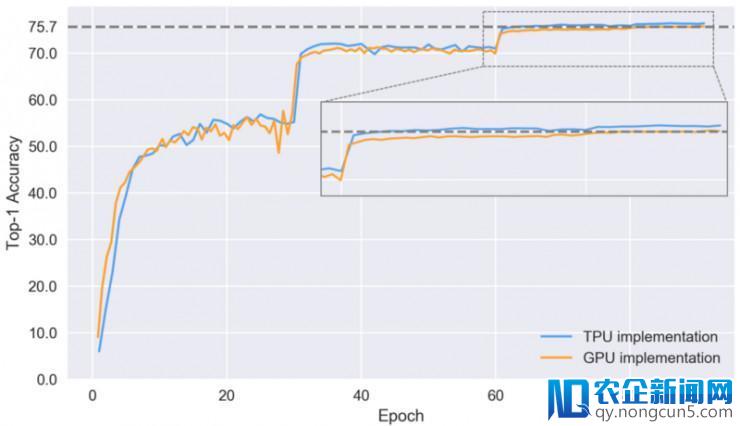
设置了验证的两个 完成的首位精确率
上表中缩小图局部首位精确率的猛烈变化,与 TPU 和 GPU 这两个 完成上模型的学习速率是相吻合的。TPU 完成上的收敛进程要好于 GPU,并在 86 个时期的模型训练后,最终到达 76.4% 的首位精确率,但是作为比照,TPU 完成则只需 64 个模型训练时期就能到达相反的首位精确率。TPU 在收敛上的提升貌似归功于更好的预处置和数据加强,但还需求更多的实验来确认这一点。
基于云端的处理方案本钱
最初,在需求到达一定的准确度的状况下,工夫和金钱本钱最为关键。我们假定准确度 75.7%(GPU 完成可完成的最高准确度)为可承受的处理方案,我们就可以计算出,基于要求的模型训练时期和模型图像每秒处置的训练速度,到达该准确度的所需本钱。这还包括计算模型在某个训练时期节点上破费的工夫和模型初始训练所需的工夫。
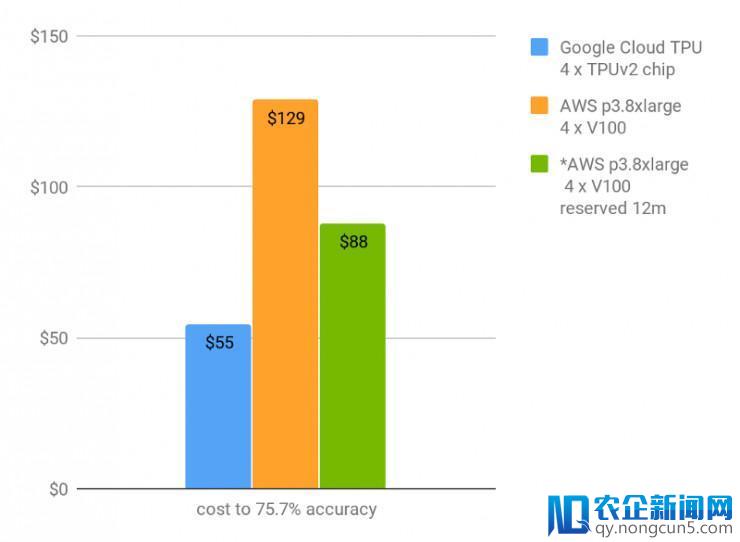
首位精确率到达 75.7% 的金钱本钱(保存 12 个月的运用周期)
正如上表所示,云端 TPU 允许用户在 9 个小时内并且破费 55 美元,就能在 ImageNet 上从零开端训练模型准确度至 75.7%,破费 73 美元能将模型收敛训练至 76.4%。虽然V100 与 TPU 的运转速度异样,但V100 破费价钱过高以及其收敛完成更慢,所以采用 TPU是分明更具性价比的处理方案。
需求再一次阐明的是,我们本次所做的比照评测的后果取决于完成的质量以及云端效劳器的标价。
另外一项两者的风趣比照将会是基于两者在能量功耗上的比拟。但是,我们如今还无法得知任何地下的 TPUv2 能量功耗信息。
总结
基于我们的实验规范,我们总结出,在 ResNet-50 上四个 TPUv2 芯片(即一个云端 TPU)和四个 GPU 的原始运转速度一样快(2% 的实验误差范围内)。我们也等待未来能经过对软件(TensorFlow 或 CUDA)优化来提升两者在平台上的运转功能和改善实验误差。
在特定成绩实例上到达特定的准确度的两者实践运用中,工夫和云端本钱最为关键。以目前的云端 TPU 定价,配合高程度的 ResNet-50 完成,在 ImageNet 上到达了令人敬佩的精确率对工夫和金钱本钱(仅破费 73 美元就能训练模型到达 76.4%的准确度)。
未来,我们还将采用来自其他范畴的不同网络架构作为模型的基准以停止更深度的评测。还有一个风趣的实验点是,关于给定的硬件平台,想要高效天时用硬件资源需求破费多少精神。举例来说,混合精度的计算可以带来分明的功能提升,但是在 GPU 和 TPU 上的完成和模型表现却是悬殊的。
最初,感激弗莱堡大学的 Hannah Bast、卡耐基梅隆大学的 David Andersen、Tim Dettmers 和 Mathias Meyer 对本次比照评测草稿文的研读与矫正。
via RiseML Blog ,雷锋网 AI 科技评论编译。
。
