
雷锋网 AI 科技评论按:视觉与言语的结合,相较于联系、检测来讲是比拟新的研讨范畴,但或许正是由于如此,在这个范畴还有很多有待探究的中央。本文为 2018 年 5 月 11 日在微软亚洲研讨院停止的 CVPR 2018 中国论文宣讲研讨会中
第四个 Session——「Vision and Language」
环节的四场论文报告。
在第一个报告中,微软亚洲研讨院的段楠博士引见了他们将 VQA(视觉问答)和 VQG(视觉成绩生成)两项义务结分解一个一致模型 iQAN 的任务。由于 VAQ 与 VQG 在某种水平上具有同构的构造和相反的输出输入,因而两者可以互相监视,以进一步同时提升两个义务的表现。
第二个报告由来自中科院自动化所黄岩引见他们在图文婚配方面的任务。不同与其他办法直接提取图像和句子的特征然后停止类似性比拟,他们以为(1)图片比语句包括更多信息;(2)全局图像特征并不一定好,于是他们提出了先对图片停止语义概念提取,再将这些语义概念停止排序,之后再停止图文婚配的比拟。
来自东南工业大学的王鹏教授在第三个报告中引见了他们在 Visual Dialog 生成方面的任务,他们提出了一种基于对立学习的看图生成对话的办法,这种办法可以在保证问答信息的真实性的状况下,维持对话的延续性。
在第四个报告中,来自华南理工大学的谭明奎教授引见了他们在 Visual Grounding 义务中的任务,也即给定图片和描绘性语句,从图中找出最相关的物体或区域。他们将这个成绩分解为三个子 attetion 成绩,并在提取其中一中数据的特征时,其他两个作为辅佐信息来提升其提取质量。
雷锋网 (大众号:雷锋网) 注:
[1]CVPR 2018中国论文宣讲研讨会由微软亚洲研讨院、清华大学媒体与网络技术教育部-微软重点实验室、商汤科技、中国计算机学会计算机视觉专委会、中国图象图形学会视觉大数据专委汇合作举行,数十位CVPR 2018 收录论文的作者在此论坛中分享其最新研讨和技术观念。研讨会共包括了 6 个session(共 22 个报告),1 个论坛,以及 20 多个 posters,AI 科技评论将为您详细报道。
[2] CVPR 2018 将于 6 月 18 - 22 日在美国盐湖城召开。据 CVPR 官网显示,往年大会有超越 3300 篇论文投稿,其中录取 979 篇;相比去年 783 篇论文,往年增长了近 25%。
更多报道请参看雷锋网:
Session 1:GAN and Synthesis
Session 2: Deep Learning
Session 3: Person Re-Identification and Tracking
Session 4: Vision and Language
Session 5: Segmentation, Detection
Session 6: Human, Face and 3D Shape
一、交融VQA和VQG
论文: Visual Question Generation as Dual Task of Visual Question Answering
报告人:段楠 - 微软亚洲研讨院
论文下载地址: https://arxiv.org/abs/1709.07192
所谓 visual question answering (VQA),即输出 images 和 open-ended questions,生成相关的 answer;而所谓 visual question generation (VQG),即输出 images 和 answers,可以生成相关的 questions。
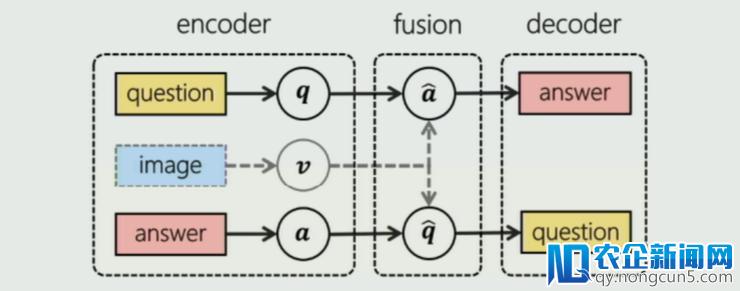
近来的 VQA 和 VQG 都是两个比拟抢手的研讨课题,但是根本上都是独立的研讨。段楠以为这两项研讨实质上具有同构的构造,即编码-交融-解码通道,不同之处只是 Q 和 A 的地位。因而他们提出将这两个义务交融进同一个端到端的框架 Invertible Question Answering Network (iQAN) 中,应用它们之间的互相关系来共同促进两者的表现。
针对 VQA 局部,他们选用了目前常用的模型 MUTAN VQA,如下图所示:
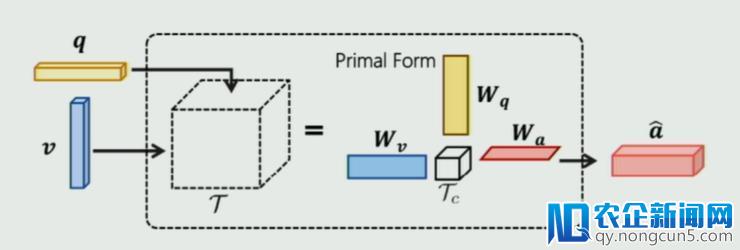
MUTAN VQA 实质上是一个双线性交融模型。思索到 VQG 与 VQA 同构,因而他们对 MUTAN 稍加改造(如下图将 Q、A 地位互换)失掉对偶的 MUTAN 方式:
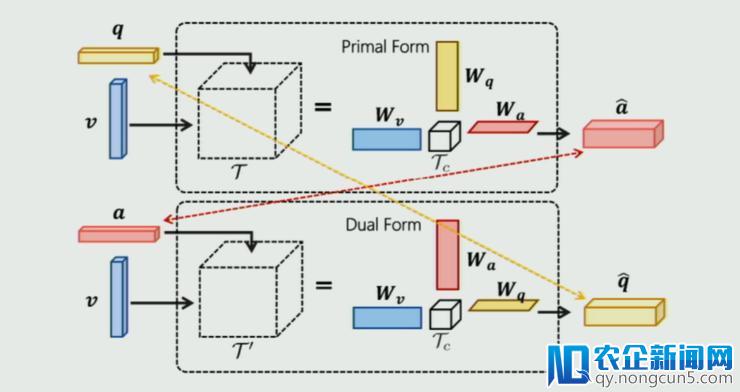
经过两个模块中 q 与 Q,a 与 A 的互相监视来提升 VQA 和 VQG 的表现。基于这样的考虑,他们构建了端到端的 iQAN 框架如下:
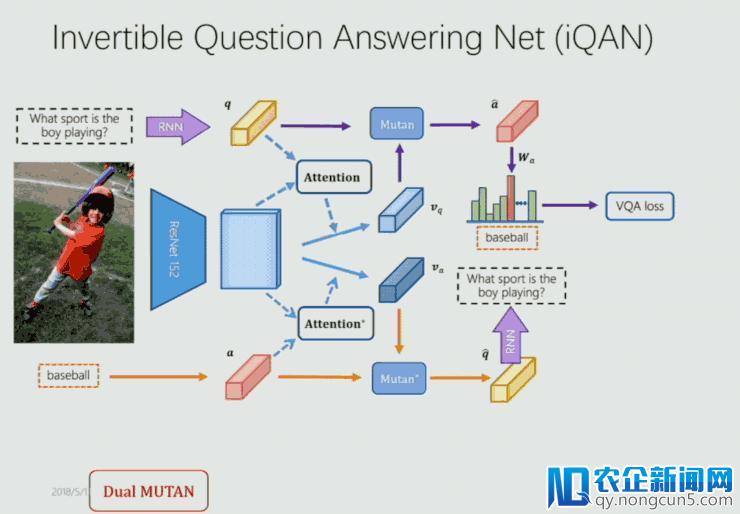
这里首先是运用 MUTAN 和 Dual MUTAN 的框架生成相应的 VQA loss 和 VQG loss。其次如方才提到,由 q 与 Q,a 与 A 的互相监视失掉 dual regularizer 的 loss。另外,image 即作为 VQA 的输出,也作为 VQG 的输出,因而它们在参数上是共享的,因而他们又做了一个 embedding sharing 的局部。
局部实验后果如下:
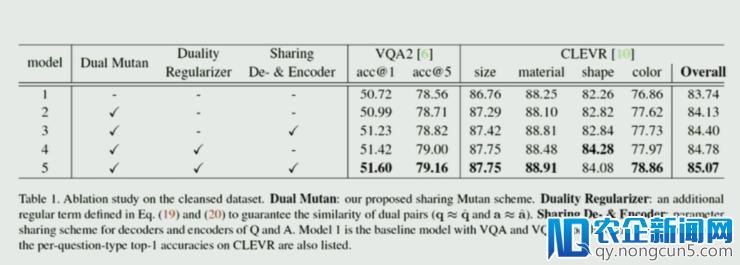
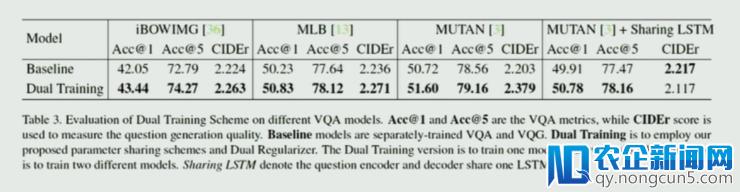
段楠提到,在这篇文章中他们运用的次要是 MUTAN 的框架,而现实上可以很容易交换成别的框架,比照实验如下,辨别运用了 iBWIMG、MLB、MUTAN 和 MUTAN+sharing LSTM:
这里是一个留意力热图后果:

二、图文婚配
论文: Learning Semantic Concepts and Order for Image and Sentence Matching
报告人:黄岩 - 中科院自动化所
论文下载地址: https://arxiv.org/abs/1712.02036
一张图片包括信息丰厚多彩,而假如单单用一个句子来描绘就会漏掉许多信息。这或许也是以后图像与文本婚配义务当中的一个成绩。黄岩等人针对此成绩,提出了学习图像语义概念和顺序,然后再停止图像/文本婚配的思绪。
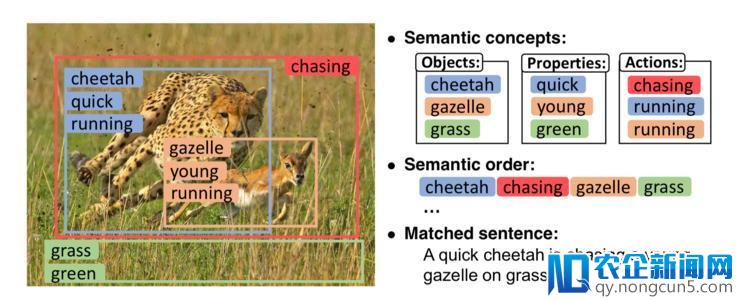
如上图所示,他们希望能先提取出图像中所包括的根本概念,例如 cheetah、gazelle、grass、green、chasing 等,包括各种事物、属性、关系等;然后学习出这些语义概念的顺序,如 cheetah chasing gazelle grass,显然这里不同的语义顺序也将招致不同的语义意义。基于这些语义概念和顺序在停止图片与文本的婚配。
全体来说,即用多区域、多标签的 CNN 来停止概念预测,用全局上下文模块以及语句生成来停止顺序学习。模型框架如下图所示:
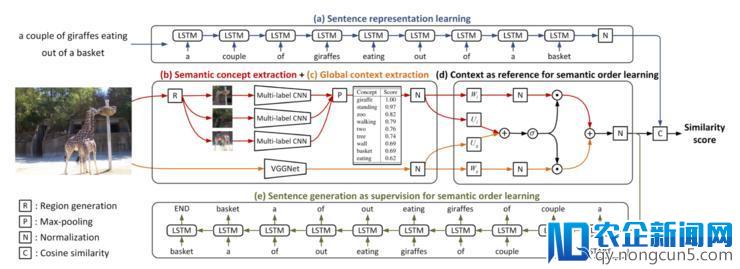
(
a
)针对句子用 LSTM 学习其特性;(
b
)运用多区域、多标签的 CNN 从图中停止语义概念提取;(
c
)运用 VGGNet 提取上下文信息;(
d
)应用提取出的语义概念和上下文的信息,例如空间地位等,经过 gated fusion unit 对语义停止排序;(
e
)此外,他们还发现现实上语句自身也包括着「顺序」的信息,因而他们应用生成的语句作为监视来学习语义顺序,进一步进步语义顺序的精确性。最初经过学习出的语义概念和顺序停止类似性打分,判别图像与句子能否婚配。
其实验后果与以后的一些 state-of-art 办法比照如下:
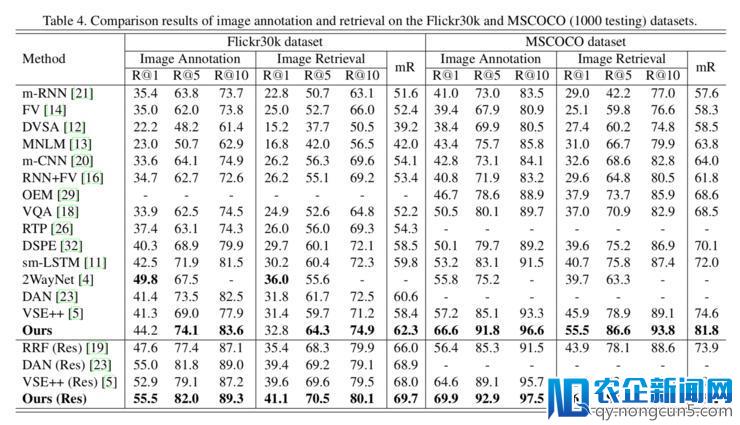
可以看出,在两个数据集中该办法的表现相比其他办法都有明显的提升。上面是一个实例:
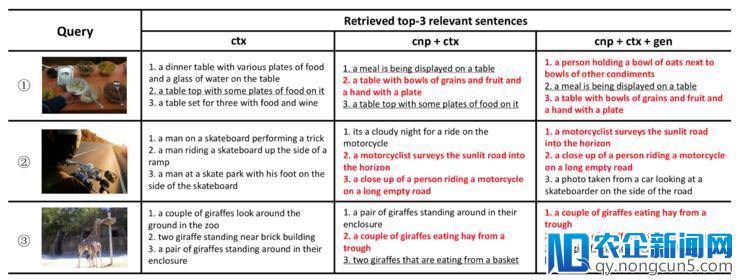
ctx = context,cnp = concept,gen = generation。其中 groundtruth 婚配语句用 白色标注 ;与 groundtruth 有相反意思的句子 以下划线标注 。
三、看图写对话
论文: Are You Talking to Me? Reasoned Visual Dialog Generation through Adversarial Learning
报告人:王鹏 - 东南工业大学
论文下载地址: https://arxiv.org/abs/1711.07613
所谓 Visual Dialog Generation,复杂来讲,即以一张图片和对话历史为条件来答复相关成绩。相比于 NLP 范畴的对话,其不同之处在于输出中除了 dialog history 和 question 外,还有一个图片信息;而相比于 Visual Answer 则多了 dialog history。如下图所示:
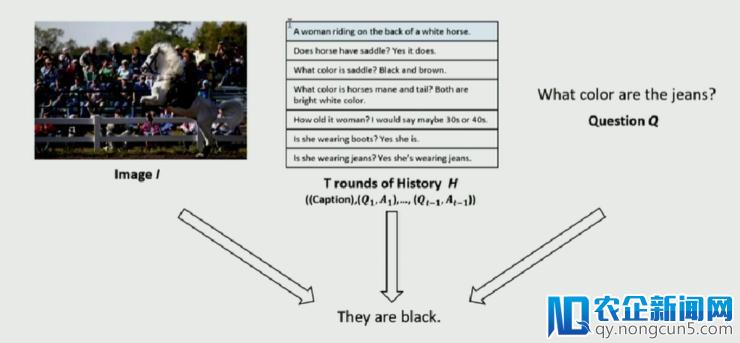
一个很自然的想法就是依然运用 Visual Answer 中的方案,将 dialog history 中的每一对对话视作图片中的一个 fact 去提取和生成。这种办法有一个缺陷,及 Visual Answer 义务的重点是针对成绩给出一个尽能够对的答案。但是关于 dialog 义务来讲,除了答复正确外,还需求维持对话的有序停止。在对话中一个好的答复是,除了答复成绩外,还要提供更多的信息,以便发问者可以依据这信息持续问下去。
基于这样的想法,王鹏等人提出了基于对立学习的方式来生成 Visual Dialog。详细来讲,他们运用了较为传统的 dialoggenerator,即针对 image、question 和 dialog history 辨别运用 CNN 和 LSTM对其停止编码,随后经过 co-attention 模型对每个 local representation 给出一个权重,然后将 localfeature 做一个带权求和从而失掉 attented feature,将该 feature 经过 LSTM 解码即可失掉一个相应的Answer。
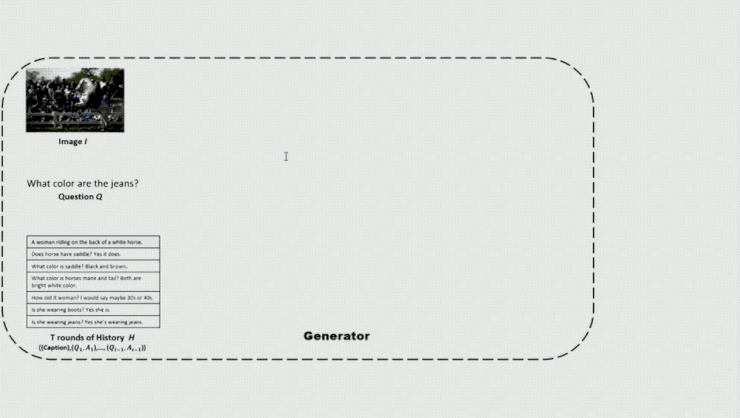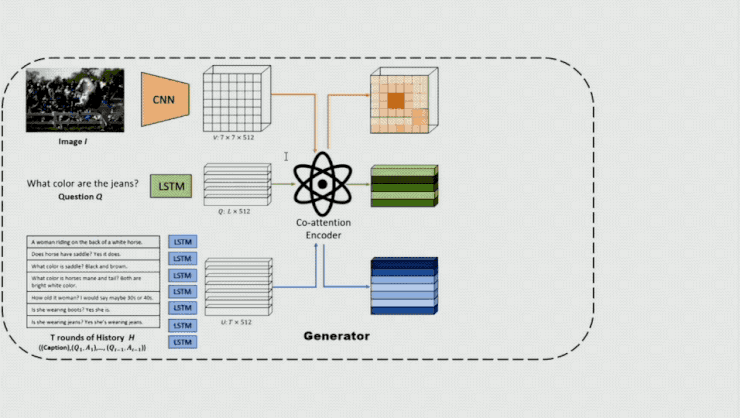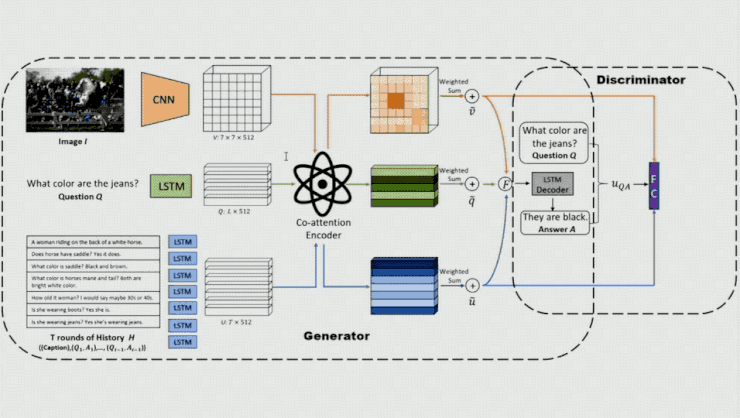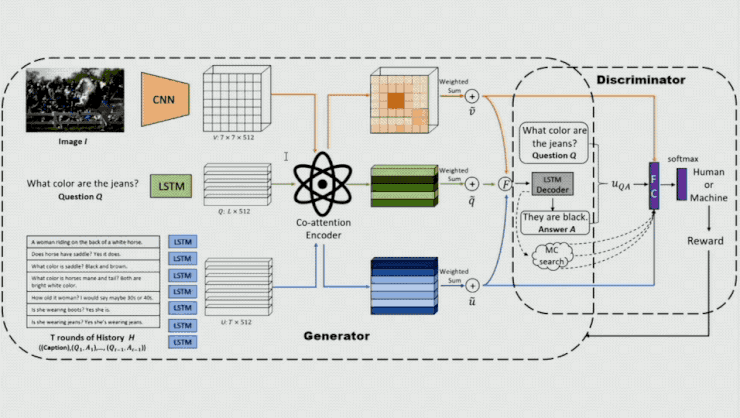
在这个模型中关键的一点是他们在模型的前面参加一个鉴别器,经过它来区分输出的答案是人发生的还是机器发生的。这里输出的不只有相应的 question 和 Answer,还有 attention 的 output,以便让鉴别器在一定的环境下剖析 Q、A 能否合理。鉴别器发生的概率将作为生成器的 reward,以对生成器的参数停止更新。
这里需求重点提一下生成器中的 Co-attention 模型,这是一个序列 Co-attention 模型,他们也曾将这个模型用在 CVPR 2017 中的一篇文章中。如下图所示:
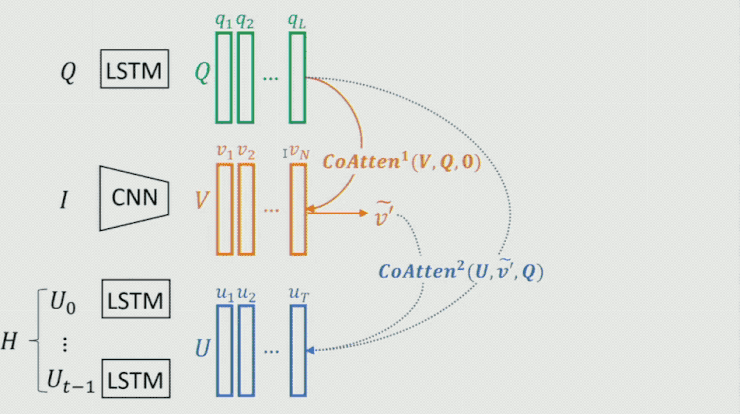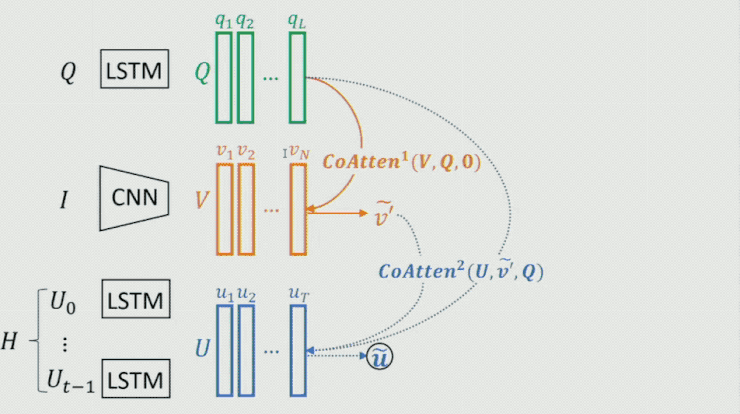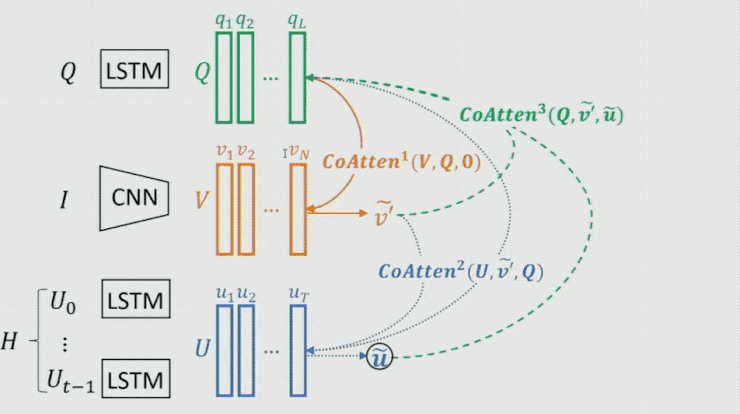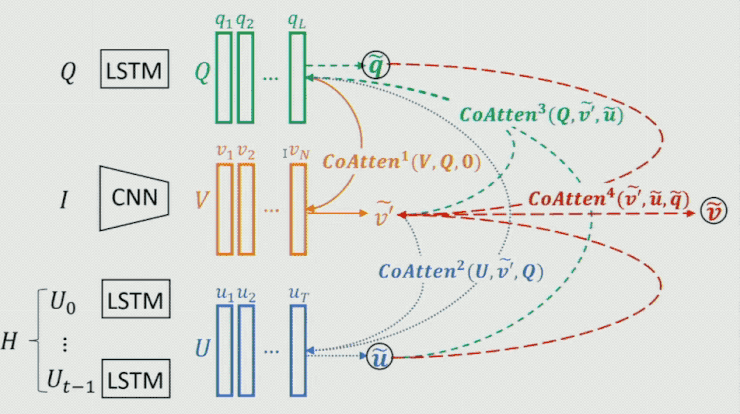
首先对 Question 做一个 attention,然后将后果作为 guidance 在 Image 上做 attention,从而失掉 image 的feature;时分再把这两个的后果作为 guidance 在 history dialog 上做 attention,失掉 history dialog 的 feature;如此往复,不时把后果进步。最终将输入 fea聚焦消费升级、多维视频、家庭场景、数字营销、新零售等创新领域,为用户提供更多元、更前沿、更贴心的产品,满足用户日益多样化、个性化的需求。ture 作为整个模型的表示。
其算法如下所示:

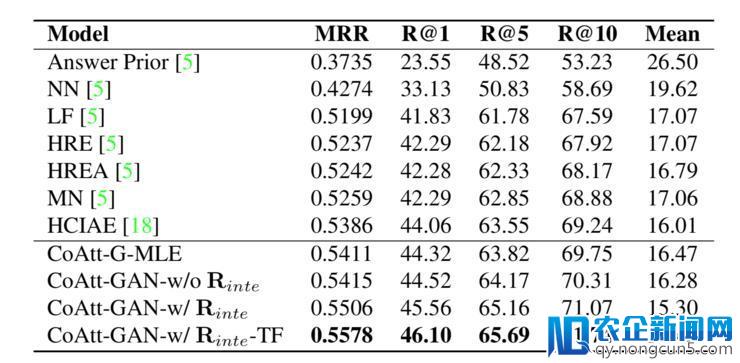
其实验后果显示比其他办法有很大提升:
一个实例如下:
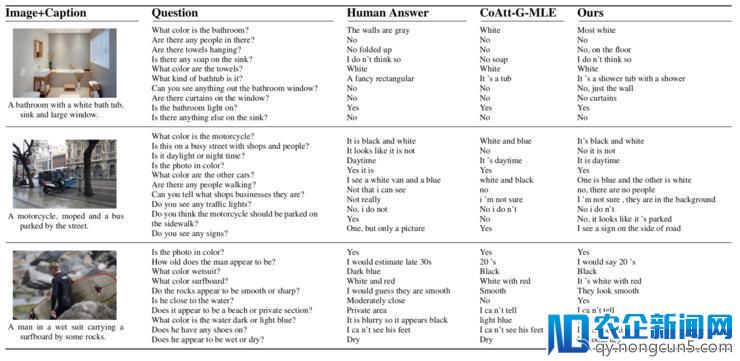
可以看出其生成对话的长度,相比其他办法要更长(这某种水平上也意味着包括更多的信息)。
四、如何找到竹筐里的熊猫?
论文:Visual grounding via accumulated attention
报告人:谭明奎 - 华南理工大学
论文下载地址:暂无
Visual Grounding 义务是指:当给定一张图片以及一句描绘性句子,从图片中找出最相关的对象或区域。抽象来说,如下图:
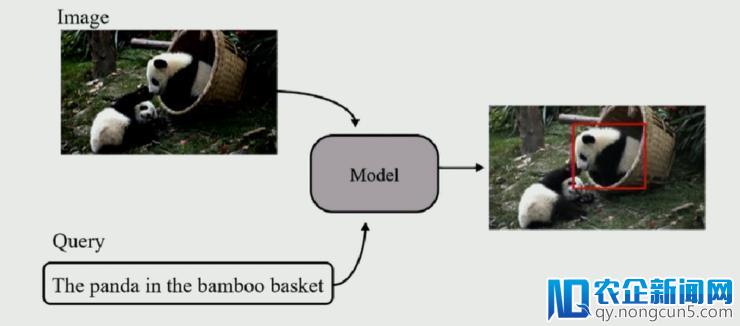
Visual Grounding 义务即从图中找出「在竹筐中的熊猫」(留意:而不是在地上的熊猫)。
据谭明奎教授引见这篇文章的任务是由华南理工大学的一名本科生完成。在文章中,作者针对此义务,提出了 Accumulate Attention 办法,将 Visual Grounding 转化为三个子成绩,即 1)定位查询文本中的关键单词;2)定位图片中的相关区域;3)寻觅目的物体。
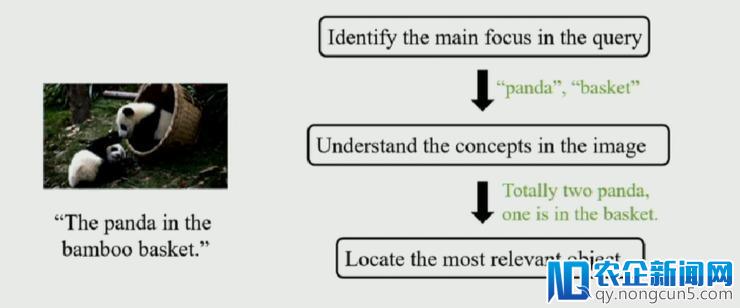
作者针对这三个子成绩辨别设计了三种 Attention 模块,辨别从文本、图像以及候选物体三种数据中提取特征。
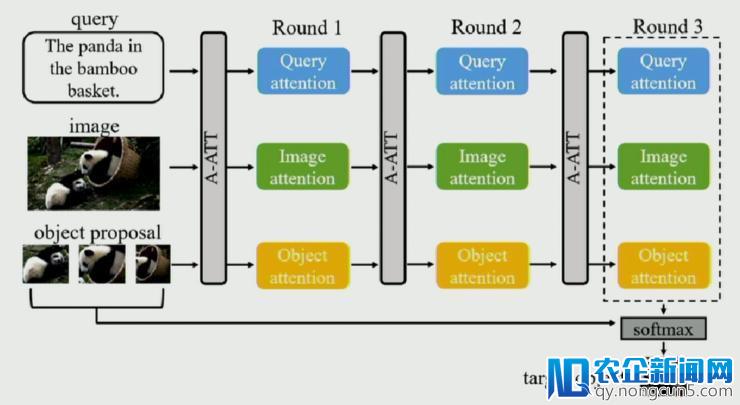
首先针对文本、图像以及物体,他们辨别运用 Hierarchical LSTM、VGG-16 以及 Faster-RCNN 来提取特征,然后运用 attention 机制计算出每个三种数据特征向量每个元素的权重。
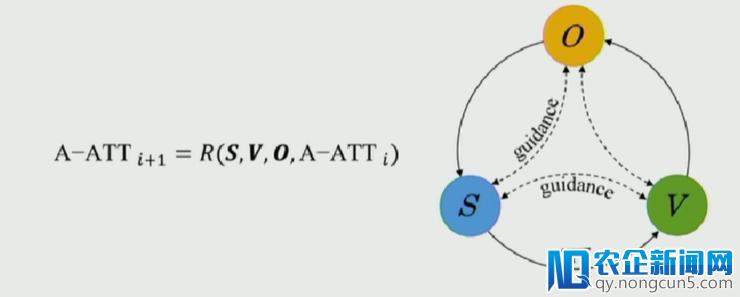
作者在提取一种特征的进程中,将另外两种数据的特征作为辅佐信息来进步特征提取的质量。Accumulate Attention 办法依照循环的方式不时对这三种数据停止特征提取,使得特征的质量不时进步,分配在目的相关的数据上的 attention 权重不时加大,而分配在有关的噪声数据上的 attention 权重则不时减小。
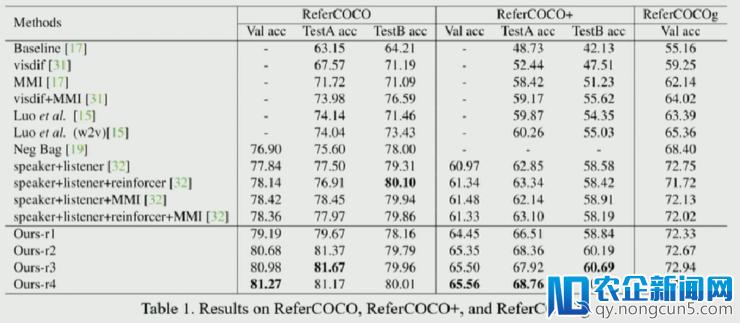
其实验标明 Accumulate Attention 办法在 ReferCOCO、ReferCOCO+、ReferCOCOg 等数据集上均获得较好的效果。(其中的 r1、r2、r3、r4 辨别代表循环轮数。)
相关文章:
CVPR 2018 中国论文分享会 之「人类、人脸及3D外形」
CVPR 2018 中国论文分享会 之「深度学习」
CVPR 2018 | 斯坦福大学提出自监视人脸模型:250Hz 单眼可重建
CVPR 2018 | 英特尔实验室让 AI 在夜间也能拍出精彩照片
。