
雷锋网 (大众号:雷锋网) AI 科技评论按 :在 Google I/O 2018 上,除了 Google 助手给餐馆打电话的场景博得现场观众的喝彩外,在用户写邮件时可预测下一句的 Smart Compose 技术异样也引得众人喝彩。近期,谷歌大脑团队首席软件工程师 Yonghui Wu 在 Google AI Po 出了这篇详细引见 Smart Compose 原理的博文,雷锋网 AI 科技评论将其内容编译如下。
Google I/O 2018 上,谷歌引见了 Gmail 中的一项新特性,智能预测拼写功用:Smart Compose,该新特性应用机器学习,交互式地为正在写邮件的用户提供补全句子的预测建议,从而让用户更快地撰写邮件。Smart Compose 基于此前智能回复(Smart Reply)技术开发而来,Smart Compose 提供了全新的方式来协助用户撰写邮件,无论用户是在回一封来件还是从草稿箱起草一封新邮件。
谷歌在开发 Smart Compose 的进程中,遭遇到了以下这些关键应战:
-
延迟:由于 Smart Compose 需基于用户的每一次输出来提供预测,所以它必需提供 100 毫秒以内的理想预测,这样用户才发觉不就任何延迟。这时分,均衡模型复杂性和推理速度就成了一个需求处理的关键难题。
-
用户规模:Gmail 拥有超越 14 亿的各种用户。为了面向一切用户提供自动组句预测,模型必需拥有足够强的建模才能,这样它才干精密地在不同上下文中提供定制建议。
-
公道性和用户隐私:在 Smart Compose 的开发进程中,谷歌需求在训练进程中处置潜在偏倚的来源,并恪守像 Smart Reply 功用一样严厉的用户隐私规范,以确保模型不会暴露用户的隐私信息。另外,谷歌的研讨人员也不具有检查用户邮件的权限,这意味着他们不得不在一个本人都无法检查的数据集上开发和训练一个机器学习零碎。
找到对的模型
比方 ngram,neural bag-of-words(BoW)和 RNN language 这种典型的言语生成模型,它们是基于前缀词序列来预测下一个词的。但是,在一封邮件中,用户在以后邮件撰写会话中打下的单词会给模型一个信号,模型会应用该信号来预测下一个单词。为了却合更多用户想表达的上下文,谷歌的模型还会应用邮件主题和此前的邮件注释(假定用户正在回复一封刚刚收到的邮件)。
谷歌的办法是包括应用额定语境的一个办法,该办法是将成绩转换成一个序列到序列(seq2seq)的机器翻译义务,其中源序列是邮件主题和上封邮件注释(假定存在上封邮件)的串联,用户正在写的邮件是目的序列。虽然该办法在预测质量上表现良好,但它的延迟要比谷歌严苛的延迟规范超出了好几个量级
为了进步预测质量,谷歌将一个 RNN-LM 神经网络与一个 BoW 模型结合起来,结合后的模型在速度上比 seq2seq 模型要快,且只细微牺牲了预测质量。在该混合算法中,谷歌经过把词嵌套们均匀分配在每个区域内,来对邮件主题和此前的邮件内容停止编码。随后谷歌将这些均匀分配后的嵌套衔接在一同,并在每次执行解码步骤时将它们提供应目的序列 RNN-LM,进程如上面的模型图解。
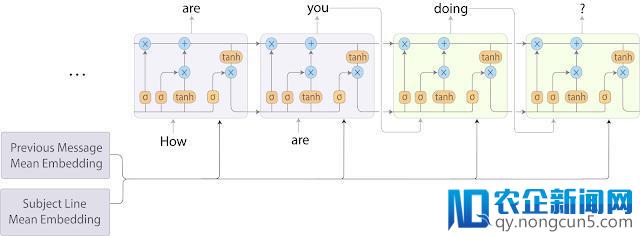
Smart Compose RNN-LM 模型架构。将邮件主题和此前邮件信息停止编码,采用的办法是将它们的词嵌套均匀分配在每一个区域内。随后,均匀后的嵌套会在每次执行解码步骤时提供应目的序列 RNN-LM。
减速模型训练和效劳
当然,一旦选定了这种建模办法,谷歌就必需调整各种模型超参数和运用超越数十亿的样原本训练这些模型,一切的这些操作都相当费时。为了完成减速,谷歌运用了一个完好 TPUv2 Pod 来执行实验。在这状况下,谷歌可以在一天之内将一个模型训练至收敛形态。
在谷歌训练出速度上更快的混合模型之后,初始版本的 Smart Compose 在一个规范 CPU 上运转时,照旧存在几百毫秒的均匀效劳延迟,这与 Smart Compose 努力预测语句来帮用户节省工夫的特点是不相符的。侥幸的是,谷歌可在推断时期运用 TPU 来大大地减速用户体验,经过分流 TPU 之上的大局部计算,谷歌可以将均匀延迟改进至几十毫秒,同时也能大大添加单一机器可处置的效劳恳求数量。
公道性和隐私
由于言语了解模型会反映人类的认知偏倚,这样会招致失掉多余的词汇联想和句子完成建议,所以在机器学习内完成公道至关重要。Caliskan et al. 在他们近期的「Semantics derived automatically from language corpora contain human-like biases」论文中指出,模型的词联想深陷于自然言语数据的偏倚数据中,这为打造任何一个言语模型都带来了相当的应战。在模型训练进程中,谷歌积极地寻觅办法来继续降低潜在的偏倚。另外,由于 Smart Compose 是基于数十亿的短语和句子停止训练,这与渣滓邮件机器学习模型的训练办法分歧,谷歌曾经停止了普遍的测试来确保,模型只记忆多种用户都运用的知识语句,关于知识语句的调查后果源自这篇论文 The Secret Sharer: Measuring Unintended Neural Network Memorization & Extracting Secrets( https://arxiv.org/abs/1802.08232 )。
将来研讨
谷歌将继续地研讨改进言语生成模型的预测质量,为此谷歌会经过运用最先进的构架(如 Transformer,RNMT+等)和试用最新、最先进的训练技术来完成这一目的。一旦模型的实验后果满足了谷歌的严厉延迟约束条件,谷歌就会把这些愈加的先进模型部署到自家产品上去。另外,谷歌还在停止结合团体言语模型的研讨,该模型的目的是给零碎添加一个新特性,让它可以愈加精确地模仿每个用户本人的写作作风。
via Google AI Blog,雷锋网 AI 科技评论编译。
。
