
雷锋网按:2018 全球人工智能与机器人峰会(CCF-GAIR)在深圳召开,峰会由中国计算机学会(CCF)主办,雷锋网 (大众号:雷锋网) 、香港中文大学(深圳)承办,失掉了深圳市保安区政府的鼎力指点,是国际人工智能和机器人学术界、工业界及投资界三大范畴的顶级交流盛会,旨在打造国际人工智能范畴最具实力的跨界交流协作平台。

在大会第一天的“AI前沿”主会场,英特尔初级首席工程师、大数据技术全球CTO戴金权带来了题为“大数据剖析+人工智能”的演讲。

戴金权担任指导英特尔全球(位于硅谷和上海)的工程团队在初级大数据剖析(包括散布式机器学习和深度学习)上的研发任务,他率领团队一手研发了基于Apache Spark 框架的散布式深度学习库 BigDL,在这次演讲中,他还着重引见了一个新产品:会后,雷锋网就BigDL和Analytics Zoo对戴金权停止了专访。
英特尔AI软件工具图谱
近一年来,英特尔重复提到的“人工智能全栈处理方案”是其人工智能战略规划的最好诠释。

戴金权引见到,英特尔不断努力于提供一个完好的端到端的全栈人工智能处理方案,从终端设备端到网络,再到数据中心的云端。
这一套处理方案的底层技术包括了至强可扩展处置器、NNP芯片、FPGA、网络以及存储技术,其上则是各种数据库、人工智能平台和详细的体验。
此次,戴金权更为详细地解释了英特尔的人工智能软件层。
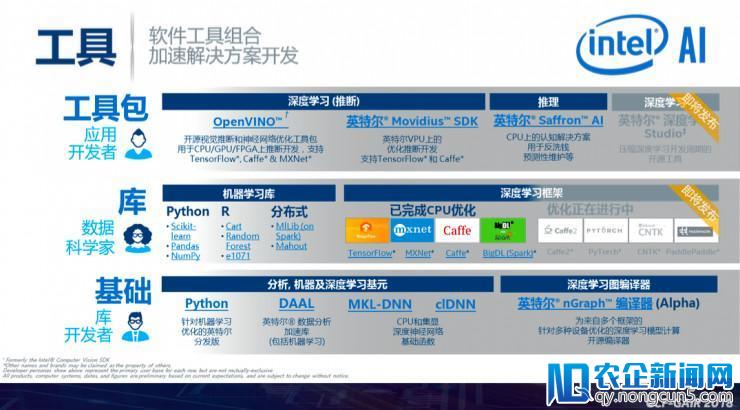
在根底层,有英特尔针对机器学习优化的英特尔发行版Python、优化的DAAL的发行版、MKL-DNN和clDNN神经网络函数的优化库、开源的nGraph编译器等;在库这一层,无机器学习库的优化、TensorFlow/MXNet/Caffe/BigDL等的优化,再到工具包这一层,有开源视觉推断和神经网络优化工具包OpenVINO、VPU上的优化推断开发的英特尔Movidius SDK、CPU上的认知处理方案英特尔Saffron AI。这些端到端的处理方案可以协助开发者更疾速地开发AI使用。

戴金权不断努力于大数据剖析,开收回基于Spark的散布式深度学习框架BigDL和Analytics Zoo,让更多的大数据用户、数据工程师、数据迷信家、数据剖析师可以更好地在大数据的平台上运用人工智能技术。
BigDL是将英特尔大数据平台与人工智能结合的产物,为什么要做这样的结合呢?
戴金权引见了三个趋向。
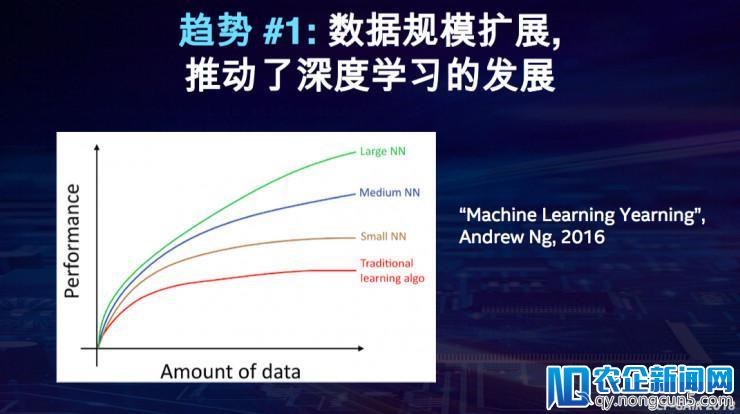
第一个趋向,明天深度学习的开展很大水平上是由于数据规模来推进的。由下图可见,随着横坐标数据规模的增长,纵坐标显示的神经网络模型就越无效,越精确。任何深度学习的零碎、框架、使用都要可以处置大规模的数据。

第二个趋向是业界大数据的开展,不论是互联网公司还是传统企业,大家都以Apache Hadoop树立起数据平台,这个平台聚集大家处置过的和未处置的数据,从而你可以将各种数据的处置、剖析和使用,使用到这个平台上。从这个意义上说,任何数据处置和剖析的框架、使用,包括深度学习的使用,都要可以十分好地和Apache Hadoop为规范的数据平台交互。
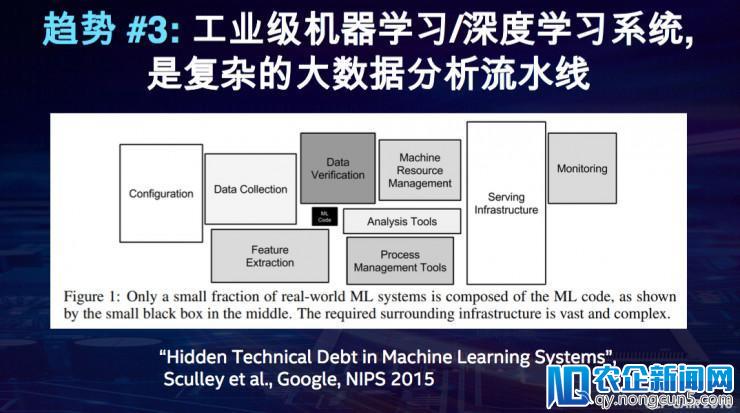
第三个趋向,深度学习的模型只是整个流程的一局部,要构建和使用深度学习模型,还无数据的导入、数据清洗、特征提取、对整个集群的资源的管理和各个使用之间对这个资源的共享等,这些任务现实上占据了机器学习或许深度学习这样一个工业级使用开发的大局部的工夫和资源。所以,数据处置、机器学习,以及算法必需很好地和现有的大数据处置的任务流整合在一同。
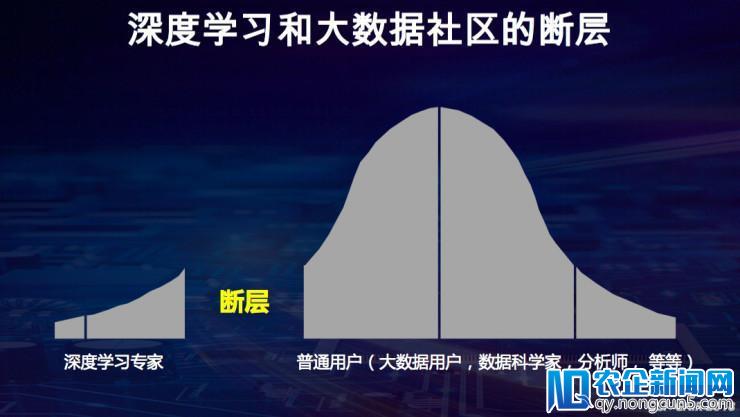
戴金权深入觉得到,在大数据处置任务和深度学习模型算法之间有很大的断层。深度学习顶尖研讨人员不时在打破模型,但是数据迷信家、剖析师、普通用户却很难将模型使用到理想的消费环境当中去。深度学习处置的一大瓶颈就是数据,特别是消费数据,都是采用散布式存储,很难将其拷贝到另一个环境再来停止处置。

在戴金权看来,Apache Spark是业界最普遍使用的散布式集群计算引擎,它外面有少量的对数据剖析处置的组件,比方说SQL的处置、实时流的处置,还有停止图剖析的库。
基于Spark推出的BigDL是Spark上规范的库、规范的组件,可以和这些大数据、生态零碎外面的不同的剖析、处置的组件十分好地整合在一同。BigDL与目前主流的深度学习框架Caffe、Torch、TensorFlow所能完成的功用相反。虽然市面上曾经有主流的深度学习框架,英特尔推出BigDL则是由于看到了将大数据剖析与人工智能结合起来的一个空白点。BigDL可以直接在现有的Hadoop和Spark的集群上运转,不需求对集群做任何修正。
戴金权通知雷锋网:“我们看到有另外一个很重要的使用场景,没有被这些现有的框架所掩盖到,我们有少量spark用户,从2007年开端开源开发,十年间曾经成为了业内数据存储处置剖析的规范,大家都曾经树立了大数据集群,下面有少量的数据,集群能够几千台,互联网公司能够几万台这样的规模。
为了深度学习和人工智能使用,难道是要把这套大数据集群完全丢弃,再另外建一套新的零碎吗?我觉得其实并不是一个最合理的途径,从某种意义下去说,应该在你现有的大数据的平台,大数据的集群下面,可以将新的深度学习、人工智能的技术,可以加出去。”
Analytics Zoo

自2017年1月英特尔开源BigDL起,曾经有普遍的协作案例。在去年年中,戴金权的团队在Apache Spark和BigDL的根底上又构建了Analytics Zoo大数据剖析和人工智能的平台。
差不多是在BigDL开源半年后,戴金权开端着手Analytics Zoo的构建。他谈到,在跟很多客户协作BigDL时,他感到,BigDL、Tensorflow这些框架里最终的AI使用还是有很长的间隔。
使用开发自身是十分复杂的任务流水线,戴金权考虑如何才干提供像Spark上的Streaming这样很方便地对特征停止处置的流水线,提供内置的模型、特征工程操作、迁移学习的流水线的支持。Analytics Zoo正是这样一个更初级别的数据剖析+AI平台,可以应用Spark的各种流水线、内置模型、特征操作等,方便用户构建深度学习端到端使用。
某种意义上它是Spark和BigDL的扩大,它的目的是方便用户开发基于大数据端到端学习的使用,除了内置的模型、内置的一些十分复杂的操作之外,它外面还提供了少量的初级的流水线的支持,可以运用Spark Dataframes、ML Pipelines的深度学习流水线,可以经过迁移学习的API构建API模型的定义,在这个根底上就可以很方便地将我们提供的Model Zoo的模型甚至端到端的参考使用,比方说异常检测等等,可以经过十分少的代码,运用这些初级的API,并且运用内置的模型,很方便地就能将一个端到端的大数据剖析加上深度学习的使用构建起来。
协作案例
戴金权引见了用户如何运用Analytics Zoo for BigDL在他们现有的大数据集群,通常是有十分大规模的至强的处置器上使用大数据的集群或许平台上,构建新的深度学习的使用。
目前,BigDL和Analytics Zoo的技术能在包括AWS、阿里云、百度云等简直一切的私有云平台上运用。

第一个例子是英特尔与京东展开的协作。京东有大约几亿张的图片存储在散布式存储零碎当中,他们想要把这几亿张图片从大数据零碎外面读出来,然后对它停止处置。在这个案例中,用了SSD的模型来试图辨认图片外面有什么物品,探后再用DeepBit的模型,将物品的特征提取出来。原来京东曾经在GPU卡上做了一些使用,但是这外面有一些成绩,包括如何处置端到端数据的流水线,包括如何进步端到端处置的效率。戴金权引见到,“当我们把整个处置的使用迁移到Spark和BigDL平台上,可以看到它提升了很多的运维的效率,运用BigDL/Spark在Intel Xeon(英特尔至强可扩展处置器)集群无效扩展,获得绝对于GPU集群3.8倍功能提升。”
AI的三个中心点在大数据、算法、算力,如今很多人以为要有足够的AI算力,非GPU不可。京东的这个案例表现了BigDL与英特尔至强可扩展处置器配合,对全体深度学习表现的提升。戴金权通知雷锋网,京东这个案例一开端是树立在多个GPU之上的,他们的团队在Caffe上训练,在开发、部署、功能方面都碰到成绩。英特尔将京西方面迁移到Spark下面,跑在1200个逻辑的核,一台效劳器支持50个逻辑,大致用了24台效劳器,应用Spark这样的端到端流水线处置,与之前用GPU的方案相比可以到达差不多3.8倍的功能提升。

第二个案例是英简单来说,创业有四步:一创意、二技术、三产品、四市场。对于停留在‘创意’阶段的团队,你们的难点不在于找钱,而在于找人。”结合自身微软背景及创业经验。特尔和MLSListings协作的案例,他们是加州的不动产买卖商,他们可以辨认用户阅读的房屋图片,为用户引荐类似的房屋。这套零碎构建在Microsoft Azure上。

第三个案例是和世界银行在AWS上协作。世界银行经过意愿者上传的世界各地的食物图片,协助大家来剖析在世界各地的物价程度。其中如何经过大数据处置对图片停止清洗、处置,再用迁移学习来构建图片分类模型是值得关注的成绩。
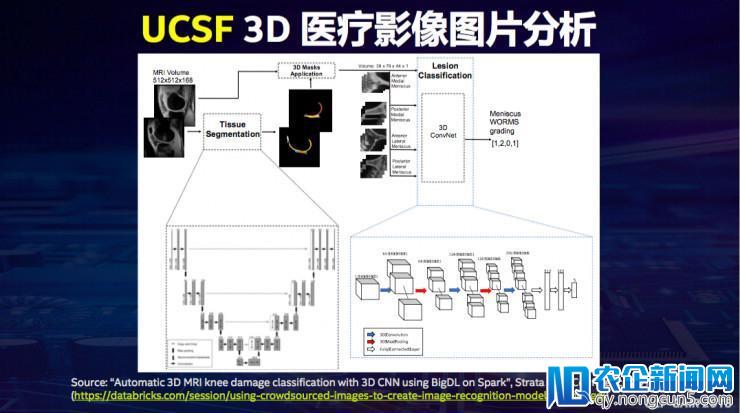
第四个案例是与UCSF的协作,经过3D的模型对医疗图象停止分类,首先对3D的MRI照片停止辨认,然后对它停止分类,可以试图诊断膝盖下面的一些病症。
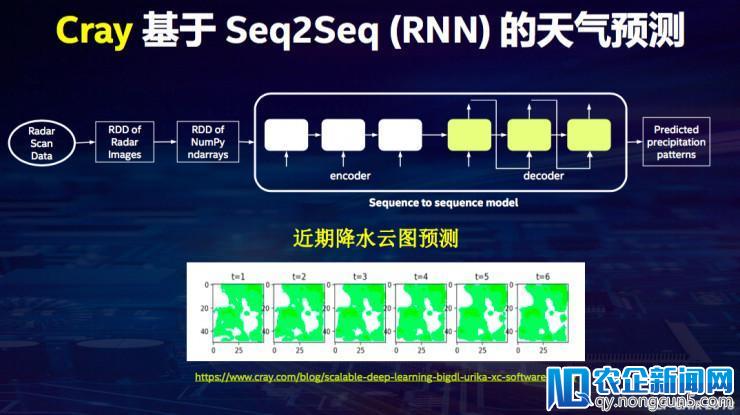
第五个案例是们和Cray公司(美国做超级电脑的公司)协作。协作内容是做近期的降水云图的预测,经过Seq2Seq的模型,把过来一小时的卫星云图做了一个序列,输出到模型外面,能帮预测下一个小时每10分钟这个卫星云图的变化,经过这个来停止一些降水的剖析。
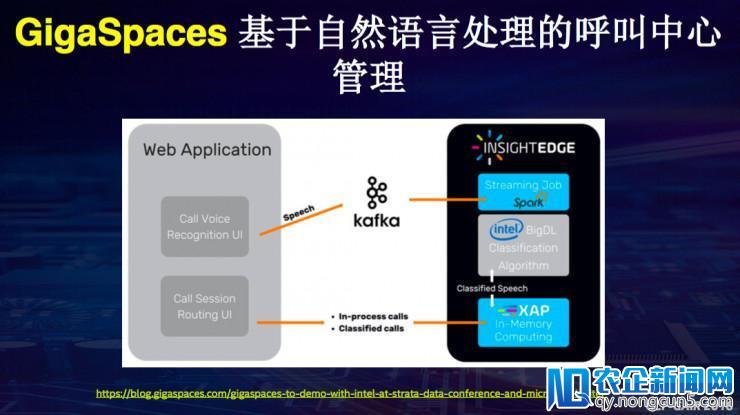
第六个案例是和GigaSpaces协作的经过基于自然言语处置对呼叫中心停止管理。当有用户打电话出去,把其语音转成文本当前,导入到BigDL零碎外面,然后对它停止实时的流式处置,运用BigDL上的文本分类模型可以晓得用户打电话出去是为什么,他是Windows出了成绩还是Mac出了成绩,自动就会把呼叫中心的电话录入到不同的部门。

最初,戴金权总结到,英特尔努力于端到端全栈人工智能处理方案。BigDL和Anaylitics Zoo努力于架起大数据和人工智能之间的桥梁,当用户已有基于Apache的大数据集群,就可以很方便地停止大数据剖析和上人工智能使用,不只可以有更高的资源应用率,还可以提升端到端的开发效率,以及提升部署效率。
相关文章:
英特尔AI事业部三位担任人解说:AI技术如何落地使用
发布新一代NNP芯片外,英特尔AI软件和使用更泄漏其AI野心
。