

和快手一同,火山小视频被各安卓商店下架有点猝不及防,却又在道理之中。
记得半个月前,有些人还沉溺在“抖音”高速增长的喜悦中,但随后央视、人民日报、第一财经周刊等央媒和中心财经媒体,相继对昔日头条及旗下的抖音产品停止了一轮违规发布广告的曝光以及价值观的批判。
在相关的许多报道中,媒体都或明或暗的强调了一点:信息流引荐技术自身早已被国际外论证了是一个成功的挪动互联网产品,但之所以呈现劣币驱赶良币的成绩还是由于运用这个技术的企业出了成绩。
也正因而,不少媒体在引述相关报道的时分都会强调,去年终,昔日头条开创人张一鸣在承受《财经》杂志专访时提出的,不以为昔日头条应该有价值观这一论调。
这在一定水平道出了昔日头条的中心成绩,但现实上更为关键的是,如今这个阶段的基于人工智能算法的内容之战,已不只仅是打破“信息茧房”这么复杂。从技术之战开端,这场信息流大战的赛点,已发作了细微的变化。
引荐精确性的PK,仍将决议于数据而非算法的技巧
对信息流来说,算法精确性是竞争重点,但真正的决胜点,却是数据。
1、数据热启动是百度完成奇袭的本源
首先需求明白一个实际,引荐算法的精确性并不是被计算出来的,而是被统计出来的(这一点在后文底层技术剖析会详细阐明),这意味着数据量越大、越相关,越能得出精确的引荐效果。
而且,由于复杂网络向量关系的存在,一个向量特征的精确性影响是呈几何分散的,数据对引荐精确性的影响是非线性增长的关系。在足够多的数据量状况下,会疾速提升,直到精确率接近100%开端变缓(毕竟100%精确非常困难,越接近越难)如图:
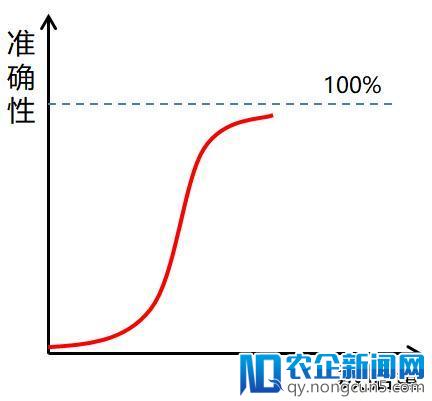
也就是说,在算法精确性这里,数据热启动的价值将变得更为重要,足够丰厚的数据,一旦介入信息流引荐算法,就可以马上完成高的精确率,追逐间距很窄。
以百度为例,其成本行搜索业务与内容直接相关,在内容大数据方面有直接优势,官方对外声称整合了千亿特征、百亿样本的数据体系,构建了囊括大到科文史哲,小到一个冷僻的小游戏的特征数据。这为其数据热启动做好了充沛的预备,而且,自动搜索表达出的用户向量特征,比经过主动点击总结的向量特征能够更为精确无效。从这样的技术角度看,百度信息流可以只用一年工夫完成其他公司三五年才达成的目的,在较短的工夫内“杠住”昔日头条并不不测。
2、只要足够大的实验平台才干让精确率“朝上走”
另一个算法精确性的成绩是引荐试算的成绩,即经过引荐的理论来反应以后算法的精确性,从而完成所谓的模型迭代。
例如,平台经过各种方式得出某类用户能够喜欢李娜,但推送李娜竞赛旧事后效果很差(点击、停留等目标低),就证明这个推断能够是不精确的,需求前往调整。这样的重复实验可以让引荐逐步接近真相。
而这些,说来说去都是硬实力的比拼,比的是谁的平台大、空间足够宽广,这会让UC这样晚期没跟上的信息流平台越来越落后(假如实验环境不够充沛,下一次迭代的精确性未必比这次好,精确率出现重复动摇而非分歧提升),而百度这样原本就凭仗搜索页面占据用户眼球的平台“庙大好念经”。
也即,算法精确性能够不是什么奇巧淫技,比来比去还是看谁的膀子粗。
技术下一程,要从冰冷的统计学走向有温度的内容尊重
上文精确性所行之事,从微观层面都是统计学的“花招”。而信息流的下半场竞争,则将更具有尊重内容自身的人文颜色。也即从“量”的上半场进入“质”的下半场。
1、算法不带价值观,但产品要有温度
张一鸣“算法不带价值观”被广为诟病,但从上文的技术推导自身而言,算法能够真的没有价值观,这些冰冷的统计学数据不关注也不能够关注到内容自身。
但异样是引荐零碎,网易云音乐在QQ音乐、虾米音乐等一众软件中独树一帜,被广为赞誉。难听的冷门歌曲、年少时听过的磁带、收音机播过的音乐,在恰当的机遇跳下去给予用户惊喜。“有温度”的产品播种用户粘性是一种必定,有温度的产品也一定是企业持久开展的必要。
异样是内容产业,信息流莫不如是。
2、“人人对等”要变成“生而不对等”
这里的转化有双重含义,首先是引荐机制不再只局限于“博眼球”的统计学需求目标,从而丢掉了优质内容。其次是打击套路写作,让上百万的内容创作者们完成真正的创作丰厚化,而不是约束于引荐机制的茧房中。
想要完成这种转化,完全寄希望于人工不太理想(虽然百度这些平台都在强调本人的人工投入),最终还是要经过技术自身去鉴别内容,打入内容的“外部”,自主判别什么是好文章、什么是好图片、什么是好视频、什么是好音乐、甚至什么是坏人(内容源)。
昔日头条在地下算法末尾就如何判别内容好坏做了一个章节,但该章节并没有太多自豪的“技术”鼓吹,阐明它仍在发力被社会期许的“好内容”。因而,假如说百度或许其他信息流平台下一阶段要彻底逾越昔日头条,“好内容”将是最适宜、最必要的角力点。
百度发力“人工智能皇冠上的明珠”NLP(自然言语处置)或许就是在走这条路。虽然同时强调本人的AI技术,但百度作为综合性科技公司绝对头条,在AI的宽度、深度上公认更有优势,在应用自然言语处置技术,对内容的质量、新颖度、情感倾向等停止深度了解和发掘方面,较昔日头条能够更有先机。
百度先于昔日头条搞出的“创作大脑”,外表上是为了更好地留住作者,而深层次能够更在于百度想在了解、区分外容好坏方面更先一步。毕竟,AI辅佐写作首先需求的就是对知识、对图像的了解,将是锻炼内容辨认技术的恰当时机。
无论如何,信息流的技术竞争一定要回到尊重作者、尊重内容的“供应侧竞争”(绝对于只关怀用户需求的需求侧竞争,它实质上文提及的统计目标集合)下去,让每一个内容集体“生而不对等”,由他评走向自我价值认同。
假如”澳网出线形势深度剖析”与“李娜3岁时干的事你相对不晓得”这样的文章不再被同等看待,最终所谓“信息茧房”等外表成绩也将迎刃而解。
而这方面,虽然百度曾经占得先机,但头条、天天快报甚至手握公认优质内容的微信入局,必将引致一场新的技术恶战。
算法流派众多,但一切归于贝叶斯
基于前文,我们能发现,在信息流引荐中,数据依然是决胜点,而信息流也必定要愈加尊重内容。而从底层技术角度,当我们回到算法的来源,也异样可以印证这些。
以目前主流的算法为例归类剖析:基于内容的引荐、协同过滤引荐、基于关联规则的引荐、基于社会化网络剖析的引荐等,用浅显的言语即可解释。
1、基于内容的引荐算法
即用户喜欢什么东西,引荐一些类似的东西。该引荐算法复杂无效,引荐后果契合人们的认知;无须用户的历史评分信息。但是,该算法必需晓得内容的特征,界定“什么才是类似”, 比方体育里的篮球、NBA、耐克……假如不能失掉足够的信息,则引荐效果较差、后果较单一。
2、协同过滤技术
即把兴味差不多的用户群体归类,然后给他们引荐相反偏好的内容。它经过协作的方式剖析用户之间的爱好,防止特征提取不完全的状况。但存在冷启动成绩,无法精确对新用户停止引荐,存在数据稀疏性成绩。有从用户动身和从内容动身两种协同,如图所示:
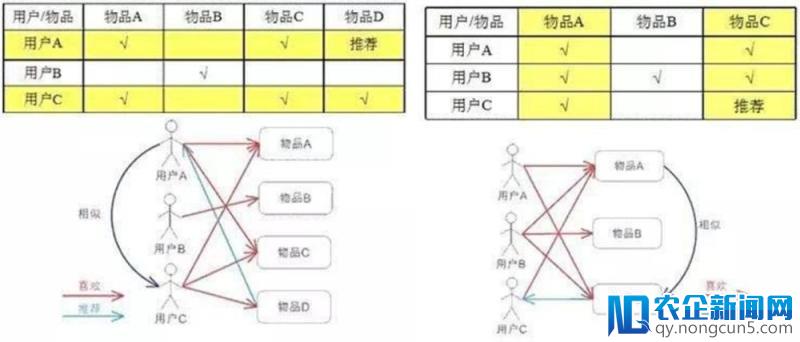
图:从用户动身和从内容动身的协同过滤引荐(来源:CSDN“数据发掘工人”博客)
3、关联规则引荐
即经过某些技术发掘大数据,树立内容之间的关联规则,后来用在实体批发,比近一年来,国家加大了对于互联网金融的管理力度,各种管理政策不断出台,不少业内人士对于互联网金融都保持着谨慎看好的态度,但是安方丹却保持了乐观的态度,她认为,互联网金融行业在当前是“风口上的大象”,技术正是这股风的原动力。方经典案例尿不湿与啤酒的搭售。在信息流范畴中,次要是用统计学的方式开掘那些外表上看不出关联的内容与内容之间的某些相关性,及相关水平。
4、社会化网络剖析
即身边的人喜欢什么,就给该用户引荐相似的内容。例如亲戚、冤家、同窗等双边关系,微博关注、微信大众号订阅等单边关系,织就一个由用户组成的节点网络,探究与剖析各节点、边的重要水平,应用这些重要关系来停止引荐。
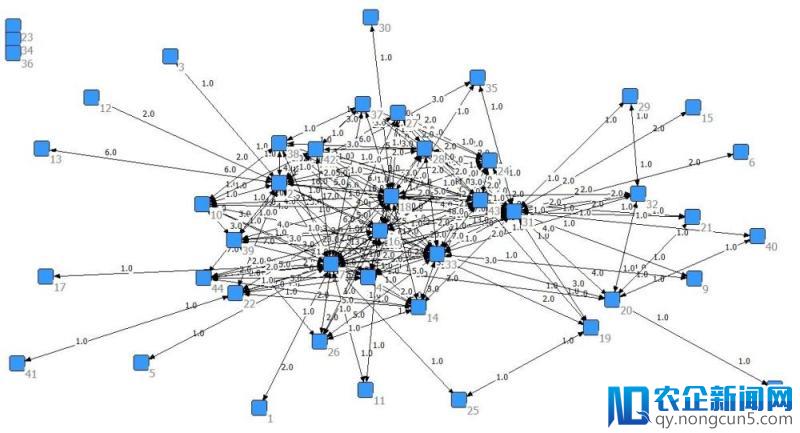
图:社会化网络剖析(来源:知乎“社会网络剖析”专栏)
上述这些次要的引荐算法,都源于贝叶斯实际。其次要处理的就是依据已发作的现实推断关联事情发作的概率。
而信息流算法中心引荐零碎正是经过应用用户的历史行为数据,剖析用户的兴味喜好并构建相应的用户模型,从待引荐的项目中选择与其兴味偏好相符的项目停止引荐。例如,在一个极简化的模型中,已知一个喜欢李娜的用户喜欢网球的概率为x,那么就可以得出喜欢网球的用户喜欢李娜的概率y,藉此引荐内容。这
种推断的精确性,就是信息流算法可以到达的精确性,其根底框架就是贝叶斯实际。可以看出,不论是基于何品种型的引荐,在算法前的机器学习层面都是由贝叶斯推断一层层、一步步堆积、衍生而来。不论最终构筑成多么庞大的体系,但它们开端的基点却是一样的,这也使得算法引荐容易陷于“信息茧房”的怪圈。
“人人对等”培养信息流“创作茧房”
在业务层面,贝叶斯的特性也不可防止地培养了“发明茧房”景象。而打破“发明茧房”,就唯有跳出当下的贝叶斯框架,靠的就是上文所言的内容尊重,从“人人对等”变成“生而不对等”,最终也给出信息流算法技术演化的应无方向。
1、概率统计根底上的算法,都是“他评体系”
主流算法,就是经过推断集体与集体之间的关系(方式可以有上文提到的多种),参考热度等评价目标,从而有目的停止引荐。例如,对一个喜欢李娜的用户引荐澳网的资讯,在引荐时就曾经依据复杂的计算(根底是贝叶斯)。由一个预期的点击率、停留工夫、点赞、评论状况计算,计算不达标的,就不会引荐出去。
在昔日头条算法发布会上,曹欢欢在讲到昔日头条的数据量时,称其有几十亿“向量特征”。所谓向量,指的是带方向,例如喜欢李娜和喜欢网球是两个“原始特征”,而“喜欢李娜→喜欢网球”才构成一个向量特征(带概率数据)。
但现实上,向量不过就是从一个点到另一个点,是点与点之间的数据关系,每一个内容集体(一篇文章、一个短视频等)都被当作一个点存在。能否被引荐,是由各种核心向量关系决议,是典型的“他评体系”(数学上,点曾经不可再联系)。
2、“人人对等”后,“创作茧房”成信息流顽疾本源
这意味着,内容和内容,在算法这里是“人人对等”的,一篇精心编撰的图文与一个拼凑热文会被厚此薄彼,都根据向量特征停止引荐。但这也形成了内容质量的“良莠不齐”。
可以说,在当下的算法体系下,内容集体真正缺乏的是“自我认可”,高质量内容源不被注重;算法更多地是“世俗评价”,算法为上,人人都在追求曝光量。
于是,在以后算法形式下,创作导向被冰冷的统计学规则限制,越来越收敛到某些高引荐、高曝光、高点击的范围内(褥羊毛有意为之,或许被环境胁迫),最终构成“创作茧房”。
算法引荐直观上形成了用户层面的“信息茧房”景象,更深层次看,则引发了内容消费者的“创作茧房”成绩。
固然,他评体系的确对加强引荐内容与用户的婚配有重要意义,提升精确性依然是算法的重要义务,但处理“创作茧房”成绩,不再把内容集体当做一个不能联系的点,而把算法扩展到内容的外部,尊重每一个内容,会是下一阶段信息流技术打破的重点。
【钛媒体作者:智能绝对论(微信id:aixdlun)】
更多精彩内容,关注钛媒体微信号(ID:taimeiti),或许下载钛媒体App
