
雷锋网 (大众号:雷锋网) AI 科技评论按:近日,李飞飞的先生 Justin Johnson 在 arXiv 上传了一篇论文:Image Generation from Scene Graphs(从场景图生成图像),提出应用构造化场景图而不是非构造化文本生成图像,该办法可以明白解析对象和对象之间关系,并可生成具有多个可辨认对象的复杂图像。

论文摘要
为了能真正了解视觉世界,模型不只要可以辨认图像,还要可以生成它们。近期在自然言语描绘生成图片方面获得了令人兴奋的停顿。这些办法在无限的范畴(例如鸟类或花卉的描绘)上提供了令人惊叹的后果,但关于具有许多对象和关系的复杂句子却很难成功复制。为了克制这个限制,作者提出了一种从场景图生成图像的办法,可以明白地推理对象及其关系。作者开发的模型运用图形卷积来处置输出图,经过预测对象的边界框和联系掩模来计算场景规划,并且将规划转换为具有级联精化网络的图像。论文作者运用对立训练网络对立一组鉴别器,以确保实践输入图像足够逼真。实验经过 Visual Genome 和 COCO-Stuff 数据集验证了其办法,定性后果和用户实验复现证明了该办法可以生成具有多个对象的复杂图像。
背景引见
我不了解的事物,我是不能够发明出来的。——Richard Feynman
创作行为的发生树立在深入了解所发明的事物的根底之上。例如,厨师要比食客更深层了解食物,小说家要比读者更深层次了解写作,电影制造者要比影迷更深层次了解电影。假如让计算机视觉零碎要真正了解视觉世界,它必需不只可以辨认图像,而且可以发生它们。
除了传递深入的视觉了解之外,生成逼真图像的办法也能够在理论中有用。在短期内,自动图像生成可以协助艺术家或图形设计师更好地任务。有一天,能够会依据我们也正在做着心目中属于未来的事业,那就是通过互联网金融创新,不断完善人与金融、货币之间的关系,让所有人都能享受到最好的金融服务 。每个用户的团体兴味喜好,公家定制图像和视频,从而取代依托算法的图像和视频搜索引擎。
作为完成这些目的的一个步骤,经过结合递归神经网络和生成对立网络,从文本到图像的分解,从自然言语描绘生成图像曾经有令人兴奋的停顿。(论文作者在 Google Cloud AI 实习时期曾经完成了这项任务)
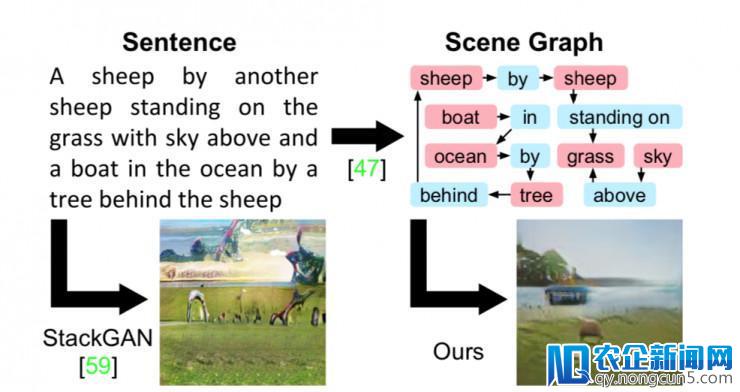
图1
句子生成图像曾经有一些最好的办法,例如StackGAN ,但它很难用真实的方式描写出有许多对象的复杂句子。论文作者经过从场景图生成图像来克制这个限制,可以明白地推断出对象及其关系。
这些办法可以在无限的区域上发生令人惊叹的效果,例如对鸟类或花朵的细致描绘。但是,如图 1 所示,从句子生成图像的次要办法遇到包括许多对象的复杂句子并不能发扬很好的效果。
句子是线性构造,一个词接一个词;但是,如图 1 所示,复杂句子传达的信息通常可以作为场景图更明白地表示为对象及其关系。场景图是图像和言语的弱小构造化表示;他们曾经被用于语义图像检索;评价和改良图像字幕。其办法也被开发用于将句子转换成场景图并用于从图像到场景图的预测。
在本文中,作者旨在经过调整场景图的生成来生成具有多对象和关系复杂的图像,从而使模型可以明白地解释对象及其关系。
这项新义务带来了新的应战。作者必需开发处置场景图输出的办法; 为此,他们运用一个图形卷积网络,沿着图形边缘传递信息。处置完图后,必需填补符号图形构造输出和二维图像输入之间的差距; 为此,经过预测图中一切对象的边界框和联系掩模来构建场景规划。事后设定好规划后,必需生成触及它的图像; 为此,运用级联精化网络(CRN),它在不时添加的空间尺度下处置规划。最初,必需确保生成的图像真实并且包括可辨认的对象; 因而针对一组用于图像补丁和生成对象的鉴别器网络停止对立训练。模型的一切组件都以端到端的方式共同窗习。
作者在两个数据集上停止实验:Visual Genome 提供了人工标注的场景图,COCO-Stuff [3] 则依据空中真实物体地位构建分解场景图。在这两个数据集上,都会展现定性后果,演示其办法生成复杂图像的才能。这些复杂图像触及输出场景图的对象和关系,并执行片面的图像联系来验证模型的每个组件。
生成图像模型的自动评价自身就是一个具有应战性的成绩,所以经过两个亚马逊 Mechanical Turk 用户研讨评价了实验后果。与 StackGAN 相比,这是一个抢先的文本到图像分解零碎,用户发现,该办法生成的后果在 68%的实验中能更好地婚配 COCO 字幕,并且包括 59%以上的可辨认对象。
实验办法
作者的目的是开发一个模型,将输出描绘对象及其关系的场景图作为输出,并生成与该图对应的逼真图像。次要的应战有三个:首先,必需开发一种处置图形构造输出的办法;其次,必需确保生成的图像触及图形指定的对象和关系;第三,必需确保分解图像真实。
作者将场景图转换为图像生成网络 f 的图像,如图 2 所示,它输出场景图 G 和噪声 z 并输入图像 I = f(G,z)。
场景图 G 由一个图形卷积网络处置,该网络给出每个物体的嵌入矢量;如图 2 和图 3 所示,图层卷积的每个层沿着图的边缘混合信息。
我们经过运用来自图卷积网络的对象嵌入向量来预测每个对象的边界框和联系掩模,从而尊重来自 G 的对象和关系;这些结合在一同构成一个场景规划,如图 2 两头所示,它充任图形和图像域之间的两头层。
输入图像 I^是运用级联精化网络(CRN)从规划生成的,如图 2 左边所示。每个模块都在处置规划,添加空间尺度,最终生成图像 I^。我们经过对一对鉴别器网络 Dimg 和 Dobj 停止对立训练 f 来生成逼真的图像,这些网络鼓舞图像 I^看起来逼真。
关于实验中每一个组件更详细的描绘,可查阅原论文:https://arxiv.org/abs/1804.01622
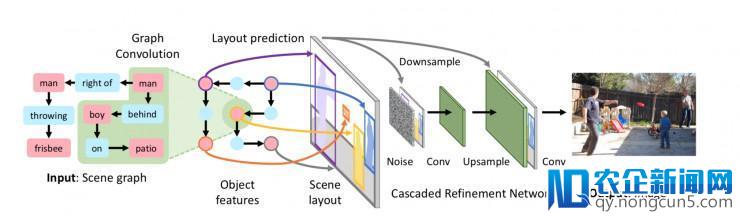
图2
图像生成网络 f 用于从场景图生成图像的概述。模型的输出是指定对象和关系的场景图; 它用图形卷积网络(图 3)停止处置,该网络沿着边缘传递信息来计算一切对象的嵌入向量。这些向量被用来预测对象的边界框和联系掩模,它们被组合构成场景规划(图 4)。运用级联细化网络(CRN)将规划转换为图像 [6]。该模型是针对一对鉴别器网络停止友好训练的。在训练时期,模型察看空中真实物体边界框和(可选)联系掩模,但是这些是在测试时由模型预测的。
图3中显示了单个图形卷积层的示例计算图。
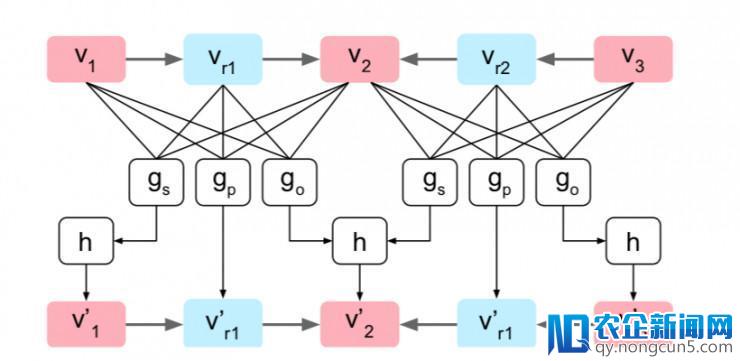
图3
计算机图形表示单一的图形变化层。 该图由三个对象o1,o2和o3以及两个边(o1,r1,o2)和(o3,r2,o2)组成。 沿着每条边,三个输出向量被传递给函数gs,gp和go; gp直接计算边的输入矢量,而gs和go计算候选矢量,它们被馈送到对称池函数h以计算对象的输入矢量。
为了生成图像,必需从图域挪动到图像域。为此,作者运用对象嵌入向量来计算场景规划,该场景规划给出了生成图像的粗略 2D 构造; 经过运用对象规划网络为每个对象预测联系掩码和边界框来计算场景规划,如图 4 所示。
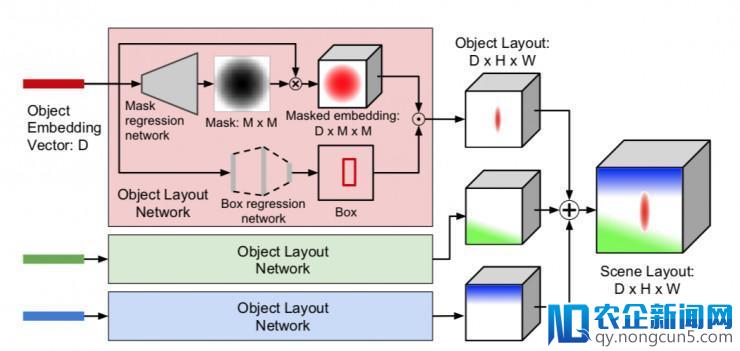
图4
图 4 经过计算场景规划从图域转移到图像域。每个对象的嵌入向量被传递给一个对象规划网络,该网络预测对象的规划,总结一切对象规划给出场景规划。对象规划网络在外部预测一个软二进制联系掩码和一个对象的边界框; 这些与运用双线性插值的嵌入向量组合以发生对象规划。

图5
图 5 运用辨别来自 Visual Genome(左四列)和 COCO(右四列)测试集的图形生成 64×64 图像为例。关于每个示例,都会显示输出场景图和手动将场景图转换为文本; 模型处置场景图并预测由一切对象的边界框和联系掩模组成的规划; 然后这个规划用于生成图像。作者还运用空中实况而非预测的场景规划显示了模型的一些后果。一些场景图具有反复的关系,如双箭头所示。为了清楚起见,疏忽了某些东西类别的遮罩,如天空,街道和水。
 图6
图6
经过作者的办法生成的图像经过 Visual Genome 训练。在每一行中,我们从左侧的复杂场景图形开端,逐渐添加更多的对象和关系向右挪动。图像触及关系,像「风筝上面的汽车」和「草地上的小船」。
局部实验后果比照
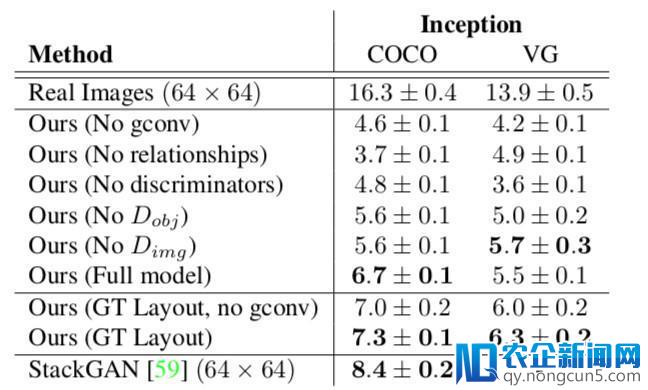
表1
表 1 是运用 Inception 分数的融化研讨。在每个数据集上,作者将测试集样本随机分红 5 组,并报告分组的均匀值和规范差。在 COCO 上,经过构建不同的分解场景图,为每个测试集图像生成五个样本。关于 StackGAN,作者为每个 COCO 测试集字幕生成一个图像,并将其 256×256 输入下采样为 64×64,以便与论文中的办法停止公道比拟。
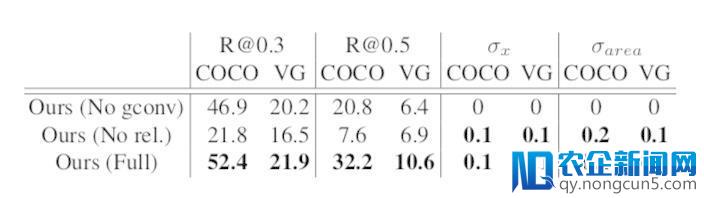
表2
表 2 是预测边界框的统计。R@t 是具有 t 的 IoU 阈值的对象调用,并且与空中实况框测量协议。σx 和σ辨别经过计算每个对象类别中框 x 地位和面积的规范偏向,然后对各个类别停止求均匀来测量框的变化。
实验后果剖析
图 5 显示了来自 Visual Genome 和 COCO 测试集的示例场景图以及运用论文作者办法生成的图像,以及预测的对象边界框和联系掩模。
从这些例子中可以清楚地看到,该办法可以生成具有多个对象的场景,甚至可以生成多个相反对象类型的实例:例如图 5(a)显示了两只羊,(d)显示了两辆巴士,(g)显示三团体,(i)显示两辆汽车。
这些例子还标明,该办法生成触及输出图关系的图像; 例如(i)看到第二个西兰花右边有一个西兰花,第二个西兰花上面有一个胡萝卜; 在(j)中,该女子正在骑马,并且该女子的腿和马的腿都曾经被适当定位。图 5 还显示了该办法运用的是地表实况而不是预测的对象规划生成的图像。
在某些状况下,该办法的预测规划能够与空中实况对象规划有很大差别。例如(k)图中没有指定鸟的地位,该办法使它站立在空中上,但是在空中真实规划中,鸟在天空中飞行。模型有时会遭到规划预测的瓶颈,比方(n)运用空中实况而不是预测规划显着进步图像质量。
在图 6 中,经过从左侧的复杂图形开端,逐渐构建更复杂的图形来演示模型生成复杂图像的才能。从这个例子中,可以看到对象的地位遭到图中关系的影响:在顶部序列中,添加「汽车在风筝上面」关系后,形成使汽车向右挪动,风筝向左挪动,从而风筝和汽车的关系也发作变化。在底部序列中,将关系「船在草地上」添加后,招致船的地位移位。
总结
在本文中,作者开发了一种从场景图生成图像的端到端的办法。 与从文本描绘生成图像的抢先办法相比,作者提出的从构造化场景图而不是非构造化文本生成图像的办法可以明白地解析对象和对象之间关系,并生成具有多个可辨认对象的复杂图像。
论文下载地址: https://arxiv.org/abs/1804.01622
雷锋网AI科技评论
雷锋网
。
