
 浪潮集团
+8
AI影响因子
活动
企业:
浪潮集团
操作:
专访
事项:
专访
浪潮集团
+8
AI影响因子
活动
企业:
浪潮集团
操作:
专访
事项:
专访
随着深度学习带来 AI 的第三次浪潮,对 AI 的相关讨论层出不穷,算法是大家关注的重点。
算法固然重要,但想做好 AI,还需求弱小的底层支撑。谷歌在训练 AlphaGo Zero 时,用到 2000 块 TPU,仅仅破费三天就完成训练。目前,企业 AI 化的需求不时加深,需求有十分弱小的计算平台来无力支撑线上推理和线下训练。
AI 计算平台触及到 GPU、CPU、TPU、FPGA 等硬件,每类硬件面前都有代表企业。英伟达 GPU 以杰出的功能,在 AI 计算中占据了相当大的市场;英特尔在 CPU 上有得天独厚的优势,并擅长规划生态,譬如将 CPU 与 FPGA 相结合;谷歌瞄准深度学习场景,发布公用 TPU 减速器。
在 4 月的浪潮云数据中心协作同伴大会(IPF2018)上,浪潮首发面向 AI 云设计的弹性 GPU 效劳器 NF5468M5,可灵敏支持 AI 模型的线下训练和线上推理。(目前,浪潮在雷锋网学术频道 AI 科技评论旗下数据库项目「 AI 影响因子 」中得分为 8 。)

图:浪潮弹性 GPU 效劳器 NF5468M5
这一效劳用具备以下功用:
-
面向线下训练对功能的需求,可支持 8 颗最高功能的 Tesla Volta GPU 以 PCI-E 或 NVlink 的高速互联。
-
面向在线推理对高能效比的需求,可支持 16 颗高能效比的 Tesla P4 GPU,适用于语音、图片、视频场景。
-
在智能视频剖析场景下,可同时处置 300 路以上 1080p 高清视频构造化。
-
在数据存储和通讯功能方面,支持 288TB 大容量存储或 32TB 固态存储,能完成高达 400Gbps 的通讯带宽和 1us 的超低延迟。
据浪潮引见,AI 云对根底架构的设计带来了新的应战,要求 AI 效劳用具备合适于不同 AI 训练场景的 GPU 灵敏拓扑、AI 线上推理的高并发低延迟与高能效比、大规模 AI 数据的存储与通讯才能。基于此,结合英伟达 GPU 芯片的良好功能以及稳健生态,浪潮做出一系列创新,推出 NF5468M5。
除了最新发布的 GPU 效劳器 NF5468M5,浪潮的效劳器还触及 CPU、FPGA。浪潮经过实测数据,剖析不同场景下人工智能计算对效劳器的功能要求,合理搭配以 CPU、GPU 和 FPGA 为中心的 AI 计算效劳器。以下是两个典型案例。
适用于多个使用场景的 FPGA 减速设备 F10A
F10A 是一款 FPGA 减速设备。基于 FPGA 具有可编程公用性,高功能及低功耗的特点,浪潮 F10A AI 线上推理减速方案针对 CNN 卷积神经网络的相互联网电子商务和移动商务消费渠道的普及,使得支付市场将在不久的将来继续呈现更加美好的增长前景。关算法停止优化和固化,可减速 ResNet 等神经网络,可以使用于图片分类、对象检测和人脸辨认等使用场景高端智能装备、新一代信息技术、新能源、新材料、新制造、新零售、新技术、生物制药等新的产业集群正在迸发活力;创新驱动、科技支撑、知识产权转化、技术转移等新的动能正在超越旧的动力,新经济成为支撑经济发展的重要力量。。
这一效劳器的单芯片峰值运算才能为 1.5 TFlops,每瓦特功能到达 42 GFlops。同时,F10A 具有灵敏的板卡内存配置,最大支持 32G 双通道内存,可以存放更多的并行义务数据。
最大支持 64 块 GPU 的 SR-AI
SR-AI 单机可完成支持 16 个 GPU 的超大扩展性节点,该方案最大支持 64 块 GPU,峰值处置才能为 512 TFlop,可支持千亿样本、万亿参数级别的模型训练。该效劳器打破了传统效劳器的 GPU/CPU 紧耦合架构,经过 PCI-e Switch 节点衔接下行的 CPU 计算/调度节点和下行的 GPU Box,完成 CPU/GPU 的独立扩容,防止传统架构晋级带来的部件过度冗余,使得 GPU 扩展无需同步配置高本钱的 IT 资源,可将本钱优化 5% 以上,随着规模上升,本钱优势愈加分明。
浪潮表示,在计算平台的选择上,企业可以在合适线下训练的计算减速节点采用浪潮抢先业界设计的浮点运算才能强、高扩展的 GPU 效劳器,或 KNM 计算减速器,而用于线上辨认的计算减速节点采用浪潮低功耗、高能效比的 GPU 效劳器,或许低功耗定制优化推理顺序的 FPGA 减速器。
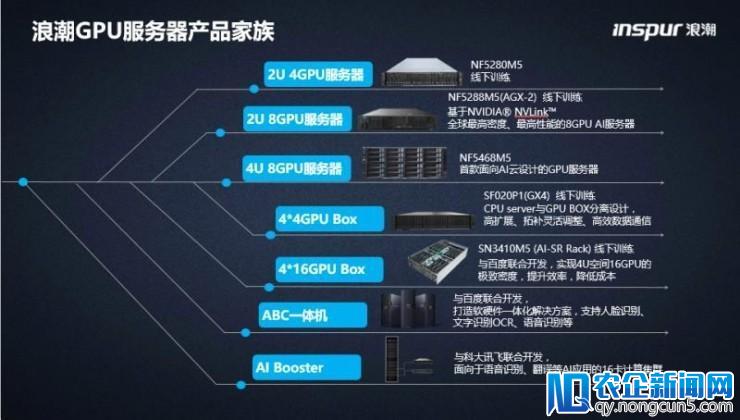
图:浪潮 GPU 效劳器产品家族
2017 年,浪潮 AI 效劳器在中国 AI 市场占有率超越 57%,阿里巴巴、腾讯和百度三家运营商 90% 以上的 AI 效劳器都来自浪潮。
关于浪潮在 AI 效劳器上的成功,浪潮 AI&HPC 总经理刘军将其归功于三个方面,一是对 GPU 的规划早,二是对行业客户的掌握——把互联网作为主航道,三是产品创新的才能和效果有保证。
日前,浪潮也地下了企业 AI 战略。
2018 年 4 月 26 日,在浪潮云数据中心协作同伴大会 IPF2018 上,浪潮发布全新 AI 品牌 TensorServer,明白传递浪潮对 AI 业务的决计与愿景。浪潮集团副总裁彭震对 TensorServer 品牌予以了诠释:「Tensor 是算法的根底元素,Server 是计算力的根底架构。AI 根底架构关于 AI 产业继续疾速安康开展至关重要。TensorServer 意在成为 AI 的承载者与赋能者,整合创新 AI 根底架构零碎,以计算开启可退化的智慧世界。」
这里的 AI 根底架构零碎涵盖平台、管理、框架、使用多个方面。
在 AI 管理上,浪潮部署 AIStation 人工智能深度学习集群管理软件。AIStation 次要面向深度学习计算集群,提供数据处置、模型开发、模型训练、推理效劳全流程效劳,支持多种深度学习框架,可以疾速部署深度学习训练环境,片面管理深度学习训练义务,为深度学惯用户提供高效易用的平台。此外,这一软件可以对计算集群的 CPU 及 GPU 资源停止一致的管理、调度及监控,无效的进步计算资源的应用率和消费率。
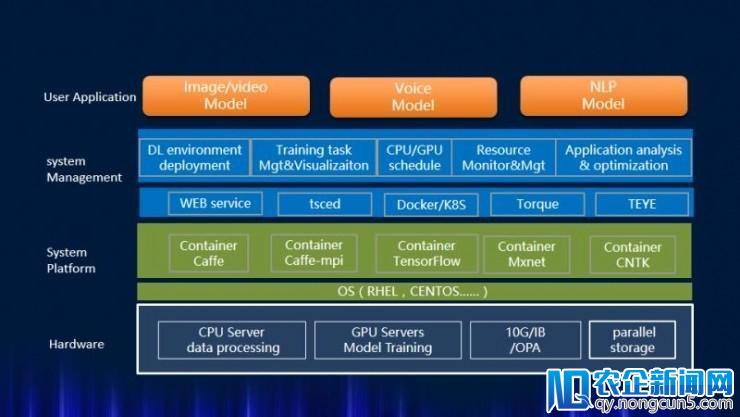
图:AIStation 零碎架构图
作为补充,浪潮还自研 Teye 使用特征剖析零碎。Teye 次要用于剖析 AI 使用顺序在 GPU 集群上运转时对硬件及零碎资源占用的状况,反映出使用顺序的运转特征、热点及瓶颈,从而协助用户最大限制的在现有平台发掘使用的计算潜力,进而为使用顺序的优化以及使用算法的调整改良提供迷信的指引方向。
而在框架上,浪潮早在 2015 年就发布 Caffe-MPI 深度学习计算框架,他们在 Caffe 架构的根底上,针对并行扩展性做出一系列创新。
据雷锋网 (大众号:雷锋网) 理解,最新版本 Caffe-MPI 在 4 节点 16 块 GPU 卡集群零碎上训练功能较单卡提升 13 倍,其每秒处置图片数量是同配置集群运转的 TensorFlow 1.0 的近 2 倍。
Caffe-MPI 设计了两层通讯形式:节点内的 GPU 卡间通讯及节点间的 RDMA 全局通讯,这极大降低了网络通讯的压力,并克制了传统通讯形式中 PCIE 与网络之间带宽不平衡的影响,同时 Caffe-MPI 还设计完成了计算和通讯的堆叠。此外,新版本 Caffe-MPI 提供了更好的 cuDNN 兼容性,用户可以无缝调用最新的 cuDNN 版本完成更大的功能提升。
除了自研深度学习框架,浪潮将深度学习框架及其依赖的库一致停止资源封装成一个镜像,之后便可以在任何支持资源封装的浪潮平台上随时加载镜像,用户可以立即开端任务,其任务环境与原始环境完全分歧,这可以无效提升消费力。目前,浪潮可封装的框架资源根本涵盖了主流的深度学习框架,包括 Caffe/Cafee-MPI、TensorFlow、CNTK、MXNet 以及 PaddlePaddle 等。
在使用减速上,雷锋网理解到浪潮的处理方案如下:
-
使用场景征询与零碎方案设计
浪潮 AI 处理方案专家与客户商榷深度学习使用场景,共同剖析计算热点和瓶颈,协助设计合适客户使用场景的零碎方案。
-
使用代码移植优化
浪潮异构使用专家可以协助客户剖析 CPU 代码特征,区分能否合适迁移至异构减速部件,并共同将代码热点停止移植优化,提升使用的计算效率,工夫更短。
-
计算减速部件功能横向评测
浪潮针对 GPU/FPGA/KNM 等主流异构减速部件拥有成熟的横向评测办法,可以协助客户选择合适的部件。
目前,浪潮的处理方案为行业 AI 转型提供赋能支撑。
浪潮与百度协作推出 ABC 一体机,这一设备集合了百度自研的集群管理软件、优化引擎和浪潮 AI 计算硬件平台,支持 PaddlePaddle、TensorFlow、Caffe 等主流深度学习框架,内嵌成熟的算法模型和云管理技术。
据浪潮引见,ABC 人脸辨认一体机支持百度人脸检测、1:1 人脸比照和 1:N 人脸查找三大人脸辨认中心才能,可以依据人脸面部的 72 个特征点辨认多种人脸属性,如性别、年龄、表情等信息,并计算人脸类似度,可用于用户身份。

图:浪潮与百度携手打造 ABC 一体机
此外,浪潮很早就开端与科大讯飞协作训练语音神经网络模型,从将模型训练从 CPU 单机上扩展到多机,然后又展开如何在 FPGA 上运转语音神经网络模型的研讨,完成更高的功能。
目前,浪潮在计算平台、管理套件、框架优化和使用减速上曾经构成无机的 AI 生态。刘军表示,关于盼望 AI 转型的企业,从客观看,极端需求这四层才能,而浪潮作为赋能者,能将这四层才能赋予这些企业,让其更疾速地完成 AI 落地。
。
