

雷锋网 AI 科技评论按:人类了解一个视觉场景的进程远比看上去复杂,我们的大脑可以依据已有的先验知识停止推理,推理的后果所能涵盖的内容也要远超出视网膜接纳到的光线形式的丰厚水平。比方,即使是第一次走进某个房间,你也能马上就认出房间里都有哪些东西、它们的地位又都在哪里。假如你看到了一张桌子上面有三条腿,你很容易推断出来很有能够它还有一条一样外形、一样颜色的第四条腿,只不过如今不在可见范围里而已。即使你没法一眼看到房间里一切的东西,你也根本上能描画出房间里的大致状况,或许想象出从另一个角度看这间房间能看到什么。
这种视觉和认知义务关于人类来说看似毫不费力,但它们对人工智能零碎来说却是一大应战。如今顶级的视觉辨认零碎都是由人类标注过的大规模图像数据集训练的。获取这种数据本钱很高,也很费时,需求人工把每个场景里的每一个物体的每一个视角都用标签标识出来。所以最初,整个场景里往往只要一小局部的物体能被标识出来,这也就限制了在这样的数据上训练的人工智能零碎的才能。随着研讨员们开发可以运转在理想世界里的机器零碎,我们也希望它们可以完全了解它们所处的环境 —— 比方最近的可以站稳的立体在哪里?沙发的材质是什么?这些暗影是哪个光源形成的?灯光开关有能够在哪里?
DeepMind 近期宣布在 Science 杂志上的论文《Neural Scene Representation and Rendering》(神经网络场景表征与渲染)就研讨了这个成绩,这篇文章是对雷锋网 (大众号:雷锋网) AI 科技评论对 DeepMind 的论文引见博客的编译。论文中他们提出了生成式讯问网络 GQN(Generative Query Ne呼吁行业者在政府部门出台相关政策标准的之前,从业者一定要规范自己的行为准则健康有序的快速发展。twork),这是一个可以让机器在场景中挪动,依据挪动进程中它们搜集到的数据停止训练,从而学会了解它们本人的所处环境的网络框架。就像婴儿和植物一样,GQN 尝试了解本人察看到的所处的世界的样子,从而停止学习。在这个进程中,GQN 根本学到了场景的大致样子、学到了它的几何特点,而且不需求人类对场景中的任何物体停止标注。
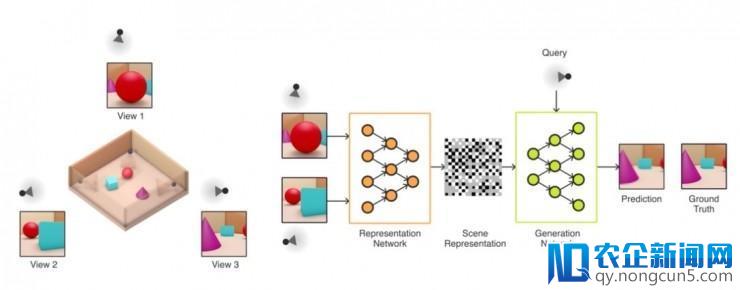
GQN 模型由两局部组成:一个表征网络和一个生成网络。表征网络把智能体察看到的画面作为输出,然后生成一个表征向量,这个向量就描绘了网络看法到的场景。生成网络接上去就会从一个之前未运用过的察看角度对场景停止预测(也可以说是「想象」)。
表征网络并不晓得生成网络要预测的视角是什么样的,所以它需求找到尽能够高效的方式、尽能够精确地表征出场景的真实规划。它的做法是捕获最重要的元素,比方物体的地位、颜色以及整个屋子的规划,在简明的散布式表征中记载上去。在训练进程中,生成器逐步学到了环境中的典型的物体、特征、物体间关系以及一些根本规律。由于有了这组共享的「概念般」的表示办法,表征网络也就可以用一种高度紧缩、笼统的方式描绘场景,然后生成器会自动补足其它必要的细节。例如,表征网络可以简约地用一组数字代表「蓝色方块」,同时生成器网络也晓得给定一个视角当前要如何把这串数字再次转化为像素点。
DeepMind 在一组模仿的 3D 世界环境中停止了控制实验,环境里有随机地位、颜色、外形、纹理的多个物体,光源是随机的,察看到的图像中也有许多遮挡。在环境中训练当时,DeepMind 的研讨人员们用 GQN 的表征网络为新的、从未见过的场景生成表征。经过实验,研讨人员们标明了 GQN 有以下几个重要的特性:
-
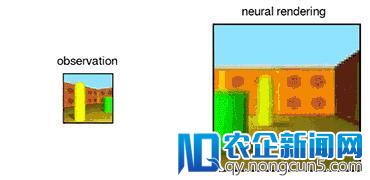
GQN 的生成网络可以以惊人的准确性重新的视角为从未见过的场景生成「想象」的图像。关于给定的场景表征和新的视角,生成网络不需求任何透视、遮挡、光照条件的先验指定,就可以生成明晰的图新生的改变世界的企业将会诞生,从而更好的服务整个人类世界,走向更高科技的智能化生活。像。这样一来,生成网络也就是一个从数据学到的不错的图像渲染器。
-
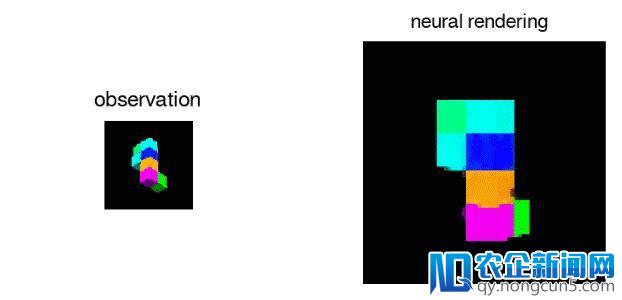
GQN 的 表征网络不需求任何物体级别的标签就可以学会计数、定位以及分类。即使网络生成的表征规模不大,GQN 关于发问视角的预测也很精确,与现实相差无几。这标明表征网络对场景的感知也很精确,比方精确描绘了上面这个场景中组成积木的方块的详细情况。
-
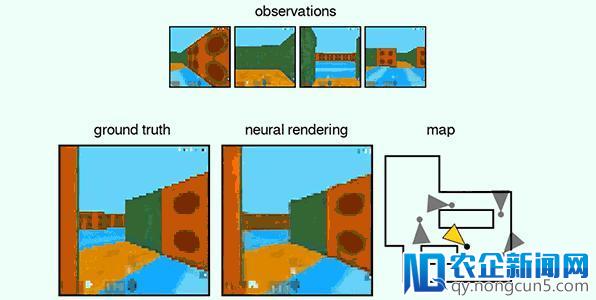
GQN 能表征、测量以及减小不确定性。它本人关于场景的认知中可以包括一定的不确定性,尤其关于场景中的局部内容不可见的状况,它可以组合多个局部的视角,构成一个分歧的全体了解。下图经过第一人称视角以及上帝视角展现了网络的这项才能。网络经过生成一系列不同的预测后果的方式展示出了不确定性,而随着智能体在迷宫中四处挪动,不确定的范围逐步减小。(图中灰色圆锥表示察看的地位,黄色圆锥表示发问的地位)
-
GQN 的表征为鲁棒、样本高效的强化学习带来了能够。把 GQN 的紧凑的表征作为输出,相比无模型的基准线智能体,目前顶级的强化学习智能体可以以更数据高效的方式停止学习,如下图所示。关于这些智能体来说,生成网络中编码的信息可以看做是存储了这些环境的「固有信息」、「通用特性」。
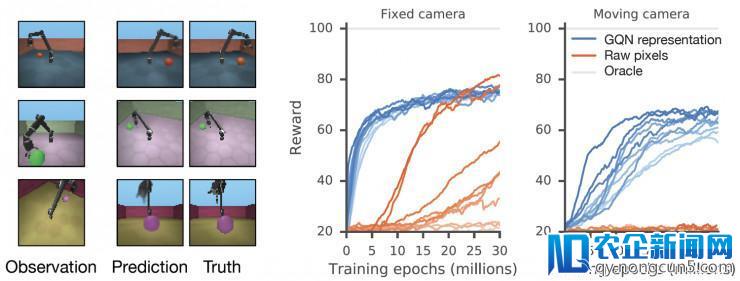
经过运用 GQN,DeepMind 的研讨人员们察看到了数据效率明显更高的战略学习,相比一个规范的、把原始像素作为数据的办法,它与环境交互的数量只需求大约 1/4 就可以失掉接近收敛级别的表现。
GQN 是基于多视角几何、生成式建模、无监视学习和预测学习方面的少量近期论文构建的,DeepMind 也在 这篇报告 中引见了相关任务。GQN 引见了一种新的方式从物理场景学习紧凑的、牢靠的表征。最关键的是,所提的办法也不需求任何专门针对范畴的工程设计或许耗时的内容标注,所以同一个模型可以用在多种不同的环境中。它还学到了一个强无力的神经网络渲染器,可以重新的视角为场景生成精确的图像。
不过 DeepMind 也表示,相比传统的计算机视觉技术,GQN 也遇到了诸多限制,目前也只尝试了在生成的场景中训练。不过,随着取得新的数据、硬件方面失掉新的提升,他们也希望将来可以在更高分辨率的、真实的场景中研讨 GQN 网络框架的使用。在后续研讨中,研讨如何把 GQN 使用到场景了解的更多层面上也是一个重要课题,比方经过关于一段工夫和空间的发问,让模型学会一些物理原理和运动知识;GQN 在虚拟理想、加强理想中也无机会失掉使用。
虽然这项办法间隔实践使用还有很长的间隔,但 DeepMind 置信这是向着全自动场景了解的目的的重要一步。
论文地址(Science版): http://science.sciencemag.org/content/sci/360/6394/1204.full.pdf
论文地址(Open Access 版): https://deepmind.com/documents/211/Neural_Scene_Representation_and_Rendering_preprint.pdf
via DeepMind Blog ,雷锋网 AI 科技评论编译
雷锋网版权文章,未经受权制止转载。概况见。
